Outline

- Context and Problem
- Jiangmen Underground Neutrino Observatory (JUNO)
- Optical Photon Simulation Problem...
- Tools to create Solution
- Optical Photon Simulation ≈ Ray Traced Image Rendering
- Rasterization and Ray tracing
- Turing Built for RTX
- BVH : Bounding Volume Hierarchy
- NVIDIA OptiX Ray Tracing Engine
- Opticks : The Solution
- Geant4 + Opticks Hybrid Workflow : External Optical Photon Simulation
- Opticks : translates G4 optical physics to CUDA/OptiX
- Opticks : translates G4 geometry to GPU, without approximation
- CUDA/OptiX Intersection functions for ~10 primitives
- CUDA/OptiX Intersection functions for Arbitrarily Complex CSG shapes
- Validation and Performance
- Random Aligned Bi-Simulation -> Direct Array Comparison
- Perfomance Scanning from 1M to 400M photons
- Overview + Links
Optical Photon Simulation ≈ Ray Traced Image Rendering
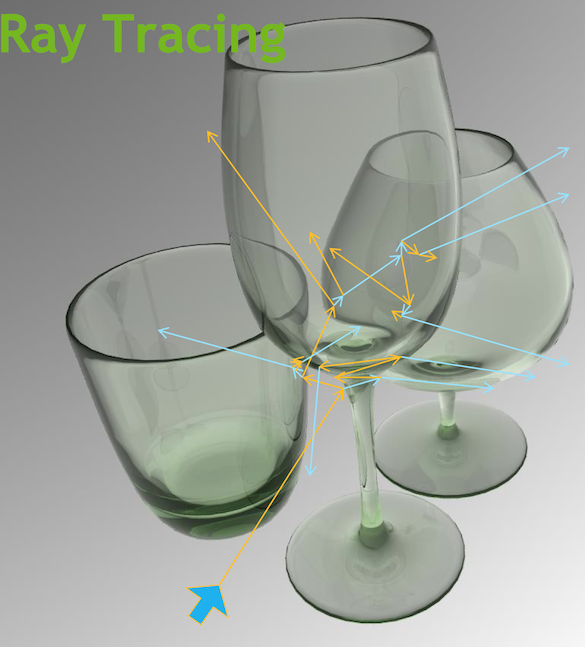
Much in common : geometry, light sources, optical physics
- simulation : photon parameters at PMT detectors
- rendering : pixel values at image plane
- both limited by ray geometry intersection, aka ray tracing
Many Applications of ray tracing :
- advertising, design, architecture, films, games,...
- -> huge efforts to improve hw+sw over 30 yrs
August 2018 : Major Ray Tracing Advance
- NVIDIA RTX Platform, Turing GPU
- ray trace dedicated hardware : RT cores
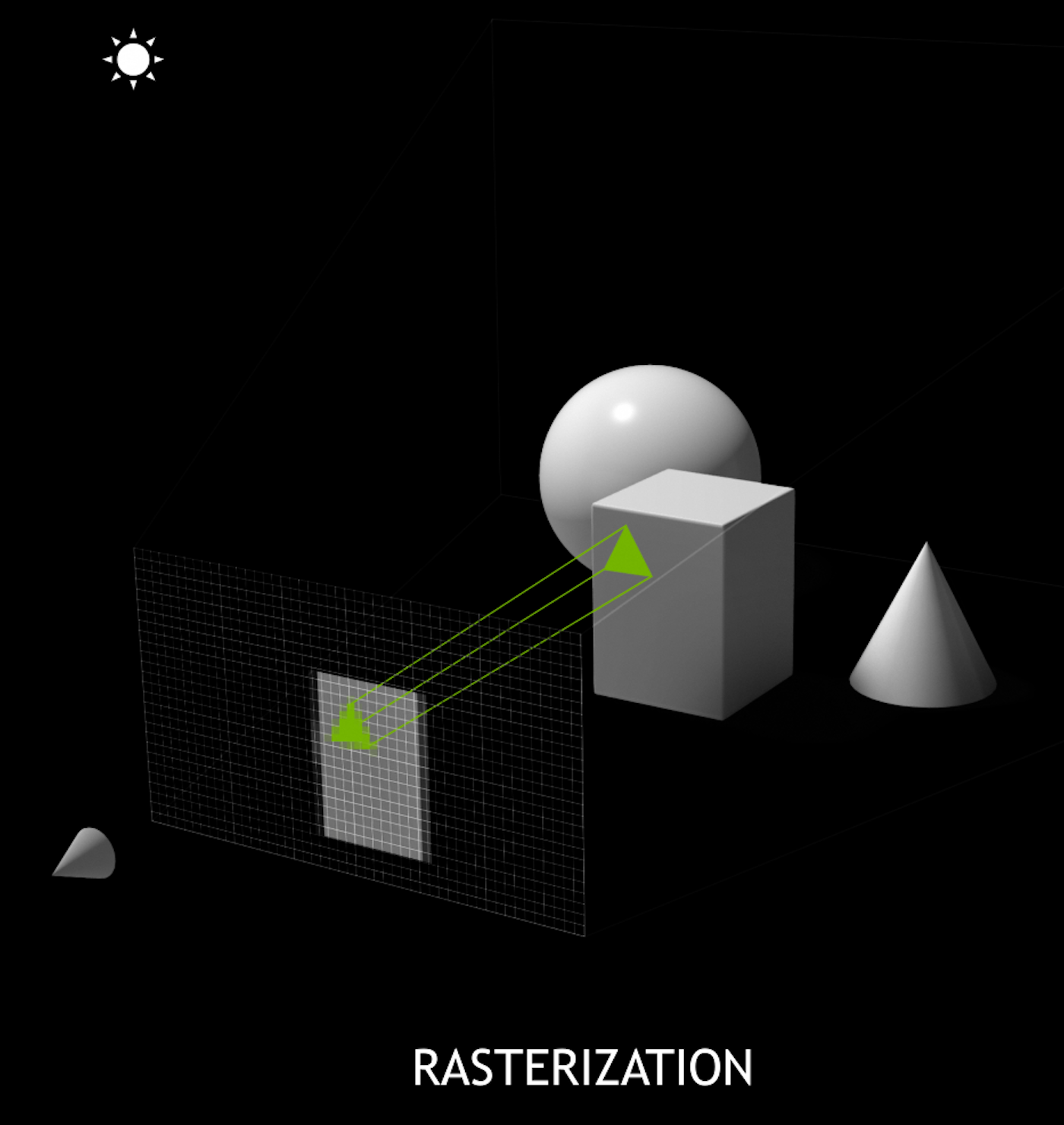
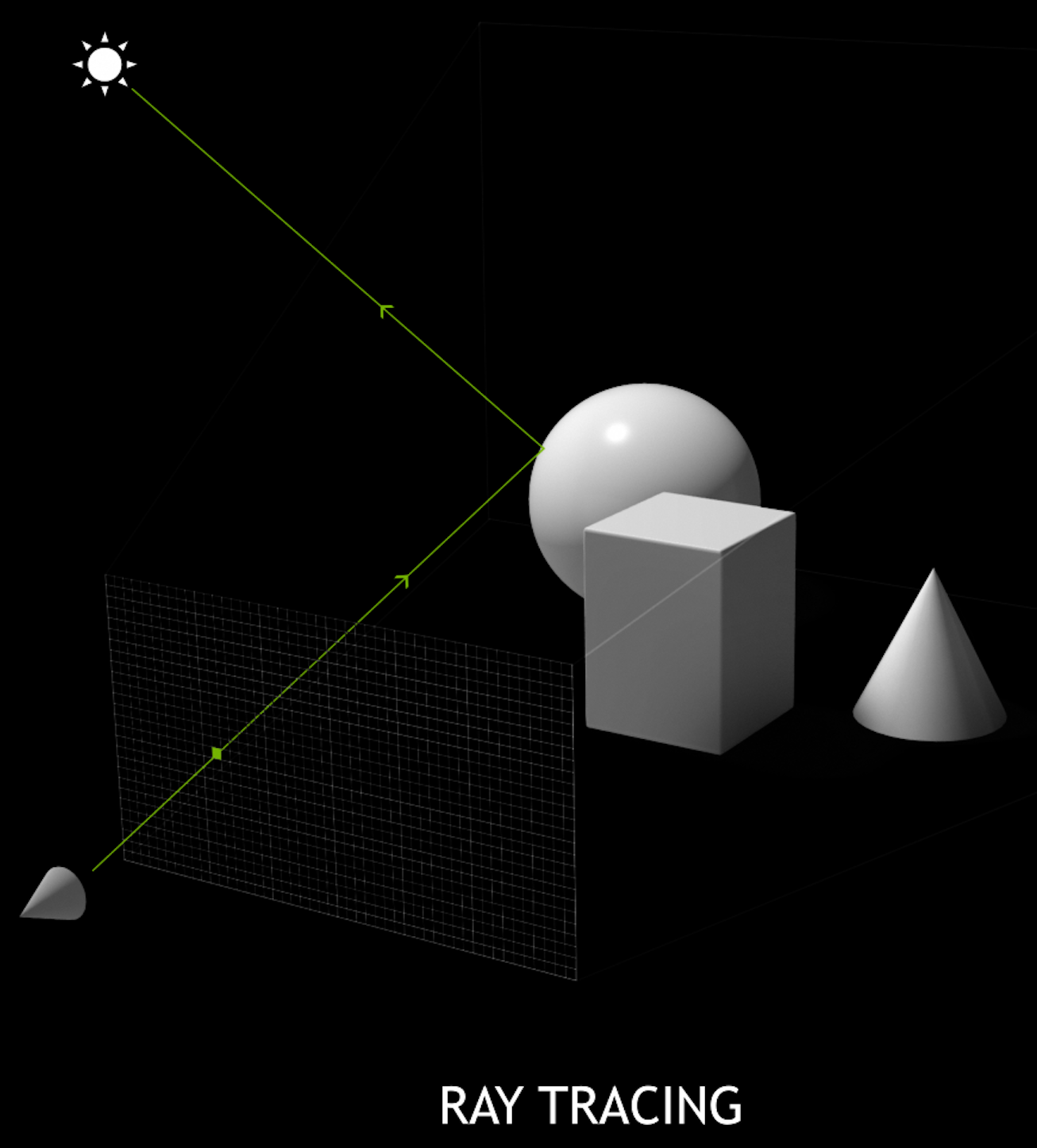
Ray-tracing vs Rasterization
NVIDIA® OptiX™ Ray Tracing Engine -- http://developer.nvidia.com/optix
Analogous to OpenGL rasterization pipeline:
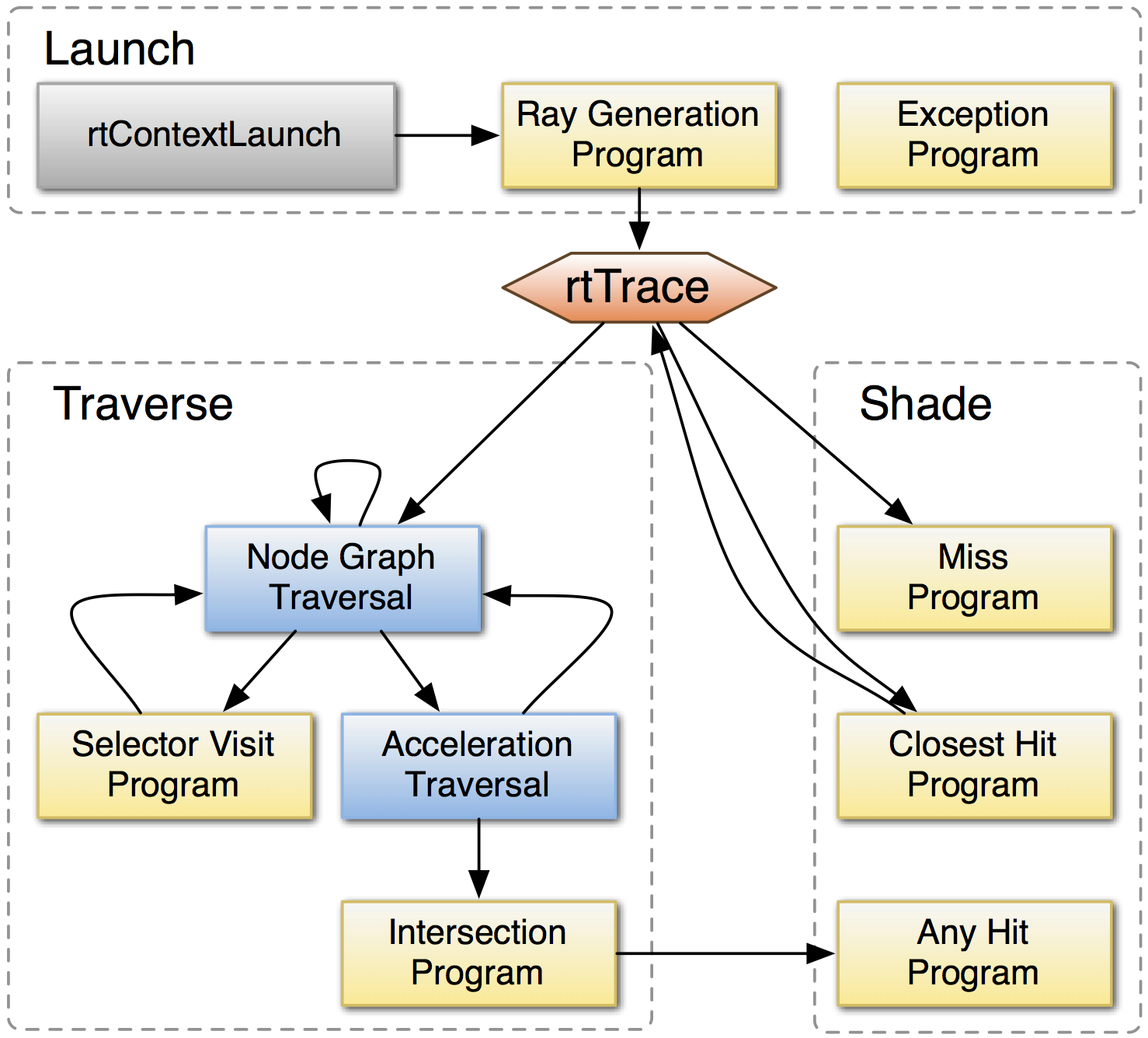
OptiX makes GPU ray tracing accessible
- accelerates ray-geometry intersections
- simple : single-ray programming model
- "...free to use within any application..."
- access RT Cores[1] with OptiX 6.0.0+ via RTX™ mode
NVIDIA expertise:
- ~linear scaling up to 4 GPUs
- acceleration structure creation + traversal (Blue)
- instanced sharing of geometry + acceleration structures
- compiler optimized for GPU ray tracing
Opticks provides (Yellow):
- ray generation program
- ray geometry intersection+bbox programs
[1] Turing RTX GPUs
Opticks : translates G4 optical physics to CUDA/OptiX
- Seeded on GPU
- associate photons -> gensteps (via seed buffer)
- Generated on GPU, using genstep param:
- number of photons to generate
- start/end position of step
- Propagated on GPU
- Only photons hitting PMTs copied to CPU
Thrust: high level C++ access to CUDA

OptiX : single-ray programming model -> line-by-line translation
- CUDA Ports of Geant4 classes
- G4Cerenkov (only generation loop)
- G4Scintillation (only generation loop)
- G4OpAbsorption
- G4OpRayleigh
- G4OpBoundaryProcess (only a few surface types)
- Modify Cerenkov + Scintillation Processes
- collect genstep, copy to GPU for generation
- avoids copying millions of photons to GPU
- Scintillator Reemission
- fraction of bulk absorbed "reborn" within same thread
- wavelength generated by reemission texture lookup
- Opticks (OptiX/Thrust GPU interoperation)
- OptiX : upload gensteps
- Thrust : seeding, distribute genstep indices to photons
- OptiX : launch photon generation and propagation
- Thrust : pullback photons that hit PMTs
- Thrust : index photon step sequences (optional)
CUDA/OptiX Intersection functions for ~10 primitives
- 3D parametric ray : ray(x,y,z;t) = rayOrigin + t * rayDirection
- implicit equation of primitive : f(x,y,z) = 0
- -> polynomial in t , roots: t > t_min -> intersection positions + surface normals

Sphere, Cylinder, Disc, Cone, Convex Polyhedron, Hyperboloid, Torus, ...
CUDA/OptiX Intersection Program for Arbitrarily Complex CSG shapes
dot(normal,rayDir) -> Enter/Exit
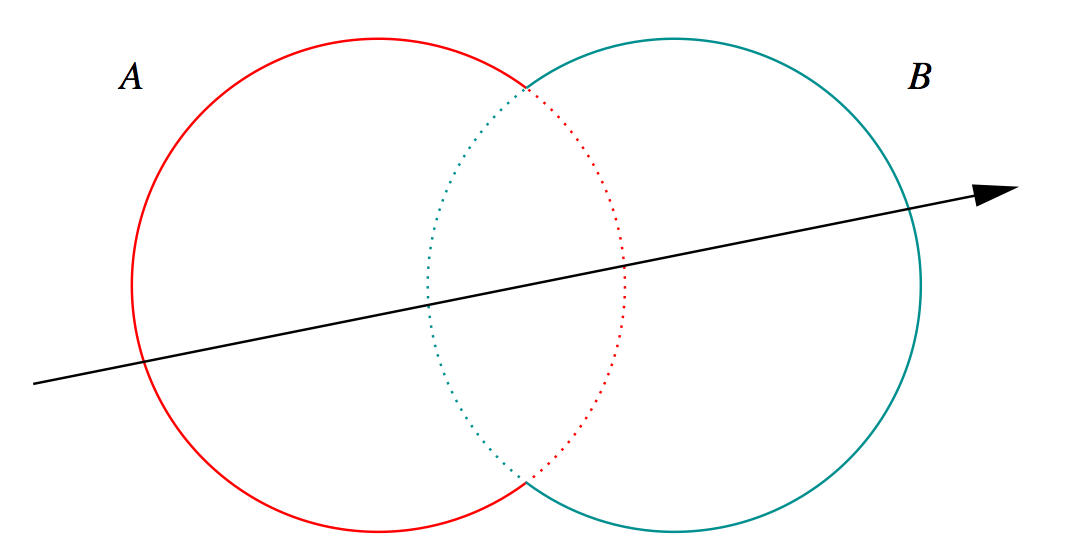
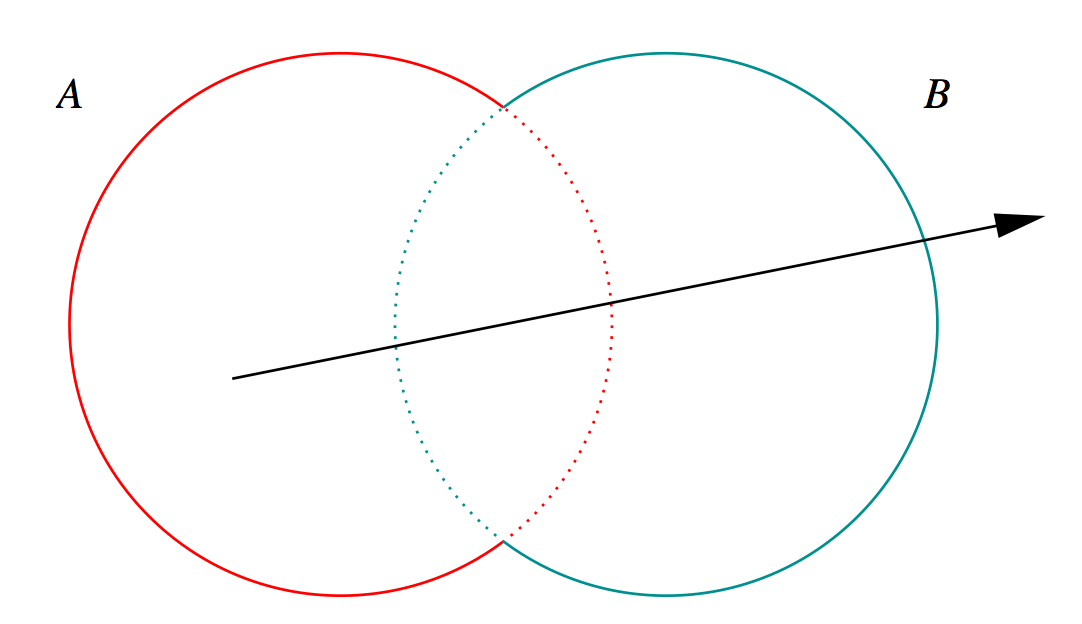
- A + B boundary not inside other
- A * B boundary inside other
Complete Binary Tree, pick between pairs of nearest intersects:
| UNION tA < tB | Enter B | Exit B | Miss B |
|---|---|---|---|
| Enter A | ReturnA | LoopA | ReturnA |
| Exit A | ReturnA | ReturnB | ReturnA |
| Miss A | ReturnB | ReturnB | ReturnMiss |
- Nearest hit intersect algorithm [1] avoids state
- sometimes Loop : advance t_min , re-intersect both
- classification shows if inside/outside
- Evaluative [2] implementation emulates recursion:
- recursion not allowed in OptiX intersect programs
- bit twiddle traversal of complete binary tree
- stacks of postorder slices and intersects
- Identical geometry to Geant4
- solving the same polynomials
- near perfect intersection match
- [1] Ray Tracing CSG Objects Using Single Hit Intersections, Andrew Kensler (2006)
- with corrections by author of XRT Raytracer http://xrt.wikidot.com/doc:csg
- [2] https://bitbucket.org/simoncblyth/opticks/src/tip/optixrap/cu/csg_intersect_boolean.h
- Similar to binary expression tree evaluation using postorder traverse.
Meeting the Challenge of JUNO Simulation with Opticks

Opticks : state-of-the-art GPU ray tracing applied to optical photon simulation and integrated with Geant4 to eliminate memory and time bottlenecks.
- Drastic speedup -> better detector understanding -> greater precision
- any simulation limited by optical photons can benefit
| https://bitbucket.org/simoncblyth/opticks | code repository |
| https://simoncblyth.bitbucket.io | presentations and videos |
| https://groups.io/g/opticks | forum/mailing list archive |
| email:opticks+subscribe@groups.io | subscribe to mailing list |