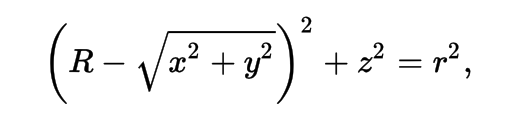nEXO + Opticks ? NVIDIA OptiX accelerated optical photon simulation ?
nEXO + Opticks ?
NVIDIA OptiX accelerated optical photon simulation ?
Open source, https://bitbucket.org/simoncblyth/opticks
Simon C Blyth, IHEP, CAS — nEXO Light Simulations Workshop, Montreal — 25 October 2024
Outline (0)

- ~15 min : Opticks Status
- (as presented at CHEP on Monday)
- ~10 min : Opticks History, early Chroma use, triangles...
- ~3 min : nEXO + Opticks ?
- difficulty : depends on your geometry
Outline (1) : Opticks Status
- Optical Photon Simulation : Context and Problem
- (JUNO) Optical Photon Simulation Problem...
- Optical photons limit many simulations => lots of interest in Opticks
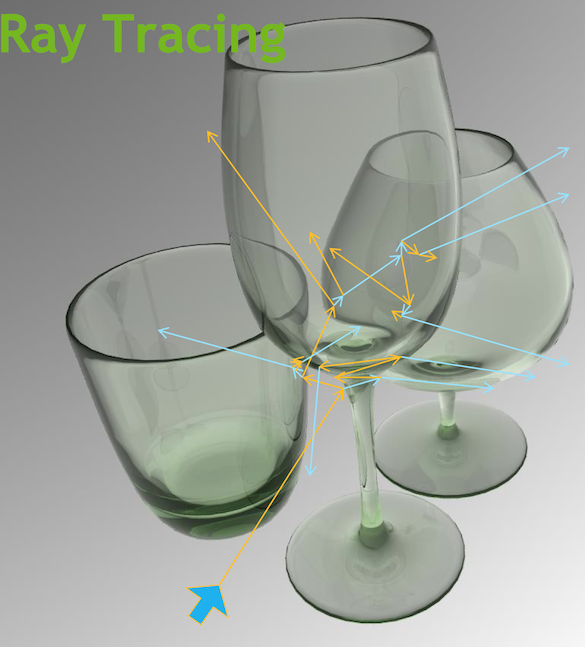
- Optical Photon Simulation ≈ Ray Traced Image Rendering
- NVIDIA RTX Generations : RT performance : ~2x every ~2 years
- NVIDIA OptiX : Ray Tracing Engine
- Opticks : Solution to Optical Photon Simulation Problem
- Geant4 + Opticks + NVIDIA OptiX : Hybrid Workflow
- Geometry Model Translation : Geant4 => CSGFoundry => NVIDIA OptiX
- Full JUNO, Opticks, OptiX 7.5/8.0
- Integrated Analytic + Triangulated Geometry (NEW)
- Interactive ray traced visualization via OpenGL/OptiX interop (NEW)
- GuideTube : Torus Triangulated
- List-node : avoids deep CSG trees
- Pure Optical TorchGenstep scan : 1M to 100M photons
- Optical simulation 4x faster 1st->3rd gen RTX
- How much parallelized speedup actually useful to overall speedup?
- Summary + Links
- Acknowledgements
(JUNO) Optical Photon Simulation Problem...
Optical photons limit many simulations => lots of interest in Opticks
| EXPT |
Reactor neutrino |
| Daya Bay |
neutrino oscillations |
| JUNO |
mass heirarchy + oscillations => NVIDIA CN Contacts |
| |
Long baseline neutrino beam |
| DUNE |
FermiLab->Sanford, LAr TPC, => Assistance from Fermilab Geant4 Group |
| |
Neutrinoless double beta decay, dark matter, other search |
| LZ |
LUX-ZEPLIN dark matter experiment, Sandford => NVIDIA US Contacts |
| LEGEND |
Large Enriched Germanium Experiment, Gran Sasso/SNOLAB |
| SABRE |
dark matter direct-detection, Australia |
| AMoRE |
Mo-based Rare process Experiment, S.Korea |
| nEXO |
next Enriched Xenon Observatory, LLNL |
| NEXT-CRAB0 |
High Pressure Gaseous Xenon TPC with a Direct VUV Camera Based Readout |
| |
Neutrino telescope |
| KM3Net |
Cubic Kilometre Neutrino Telescope, Mediterranean |
| IceCube |
IceCube Neutrino Observatory, South Pole |
| |
Air shower : gamma-ray and cosmic-ray observatory |
| LHAASO |
Large High Altitude Air Shower Observatory, Sichuan |
| |
Accelerator |
| LHCb-RICH |
LHCb ring imaging Cherenkov sub-detector, CERN => NVIDIA EU Contacts |
Optical Photon Simulation ≈ Ray Traced Image Rendering
- simulation
- photon parameters at sensors (PMTs)
- rendering
- pixel values at image plane
Much in common : geometry, light sources, optical physics
- both limited by ray geometry intersection, aka ray tracing
Many Applications of ray tracing :
- advertising, design, architecture, films, games,...
- -> huge efforts to improve hw+sw over 30 yrs
NVIDIA RTX Generations
- RT Core : ray trace dedicated GPU hardware
- Each gen : large ray tracing improvements:
- Blackwell (2024?5) Expect: ~2x ray trace over Ada
- Ada (2022) ~2x ray trace over Ampere
- Ampere (2020) ~2x ray trace over Turing (2018)
- NVIDIA Blackwell 4th Gen RTX : expected Q1 2025
ray trace performance : ~2x every ~2 years
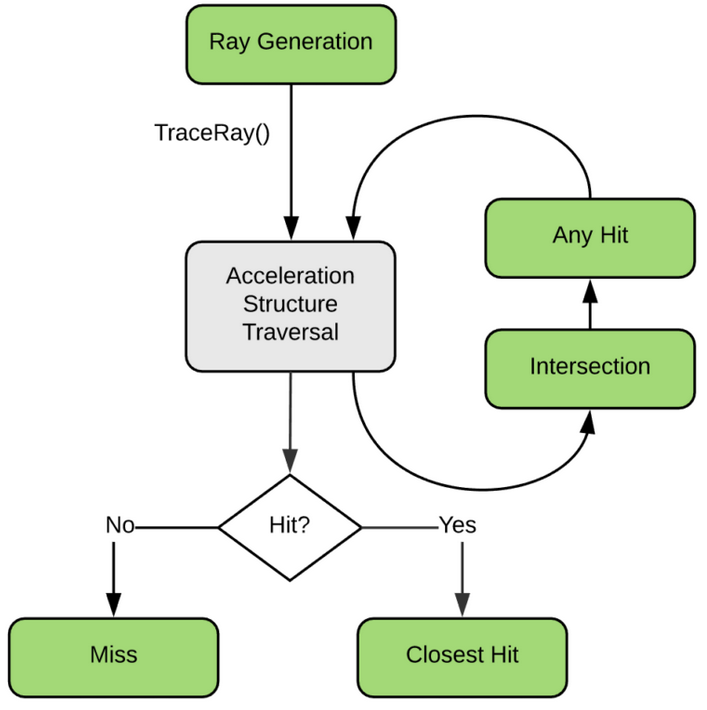
NVIDIA® OptiX™ Ray Tracing Engine -- Accessible GPU Ray Tracing
OptiX makes GPU ray tracing accessible
- Programmable GPU-accelerated Ray-Tracing Pipeline
- Single-ray shader programming model using CUDA
- ray tracing acceleration using RT Cores (RTX GPUs)
- "...free to use within any application..."
OptiX features
- acceleration structure creation + traversal (eg BVH)
- instanced sharing of geometry + acceleration structures
- compiler optimized for GPU ray tracing
User provides (Green):
- ray generation
- geometry bounding boxes
- intersect functions
- instance transforms
Latest Release : NVIDIA® OptiX™ 8.0.0 (Aug 2023) NEW:
- Shader Execution Reordering (SER) (Ada: up to 2x)
- SER: reduced execution+data divergence (on-the-fly)
Geant4 + Opticks + NVIDIA OptiX : Hybrid Workflow
| https://bitbucket.org/simoncblyth/opticks |
Opticks API : split according to dependency -- Optical photons are GPU "resident", only hits need to be copied to CPU memory
Geometry Model Translation : Geant4 => CSGFoundry => NVIDIA OptiX 7/8
Geant4 Geometry Model (JUNO: 400k PV, deep hierarchy)
| PV |
G4VPhysicalVolume |
placed, refs LV |
| LV |
G4LogicalVolume |
unplaced, refs SO |
| SO |
G4VSolid,G4BooleanSolid |
binary tree of SO "nodes" |
Opticks CSGFoundry Geometry Model (index references)
| struct |
Notes |
Geant4 Equivalent |
|---|
| CSGFoundry |
vectors of the below, easily serialized + uploaded + used on GPU |
None |
| qat4 |
4x4 transform refs CSGSolid using "spare" 4th column (becomes IAS) |
Transforms ref from PV |
| CSGSolid |
refs sequence of CSGPrim |
Grouped Vols + Remainder |
| CSGPrim |
bbox, refs sequence of CSGNode, root of CSG Tree of nodes |
root G4VSolid |
| CSGNode |
CSG node parameters (JUNO: ~23k CSGNode) |
node G4VSolid |
NVIDIA OptiX 7/8 Geometry Acceleration Structures (JUNO: 1 IAS + 10 GAS, 2-level hierarchy)
| IAS |
Instance Acceleration Structures |
JUNO: 1 IAS created from vector of ~50k qat4 (JUNO) |
| GAS |
Geometry Acceleration Structures |
JUNO: 10 GAS created from 10 CSGSolid (which refs CSGPrim,CSGNode ) |
JUNO : Geant4 ~400k volumes "factorized" into 1 OptiX IAS referencing ~10 GAS
Ada_cxr_overview_emm_t0_elv_t_moi__ALL.jpg
Analytic + triangulated geometry
- default : analytic CSG solids
- user can name solids for triangulation
- avoids issue with toruses + complex solids
- BUT : approximate geometry
- triangulation from G4Polyhedron
- config per-solid NumberOfRotationSteps by envvars
- uses OptiX "built-in" triangle intersection
- NEW FEATURE (2024)
- Integration of analytic + triangulated geometry
cxr_min__eye_1,0,0__zoom_1__tmin_0.5__sSurftube_0V1_0:0:-1.jpg
Interactive ray traced visualization via OpenGL/OptiX interop
initial viewpoint, geometry exclusions via envvars
WASDQE+mouse 3D navigation
Ada_cxr_min__eye_1,0,0__zoom_1__tmin_0.5__sSurftube_0V1_0:0:-100000.jpg
Render on NVIDIA RTX 5000 Ada Generation in 0.0060 s (not 0.0200 s)
GuideTube : Torus Triangulated
- GuideTube (39*2*2 = 156 G4Torus)
- split in phi segments, radius breaks
Intersect with torus expensive on GPU
- requires double precision to solve quartic
- even with double precision analytic solution imprecise
- numerical approach favored => triangulation
Triangulation using G4Polyhedron
G4Poly..::SetNumberOfRotationSteps
| |
NumberOfRotationSteps |
|---|
| HepPolyhedron Default |
24 |
| Top Right |
48 |
| Bottom Right |
480 |
Adjustable: precision of intersect, number of triangles
GPUs evolved for triangles => fast even with many
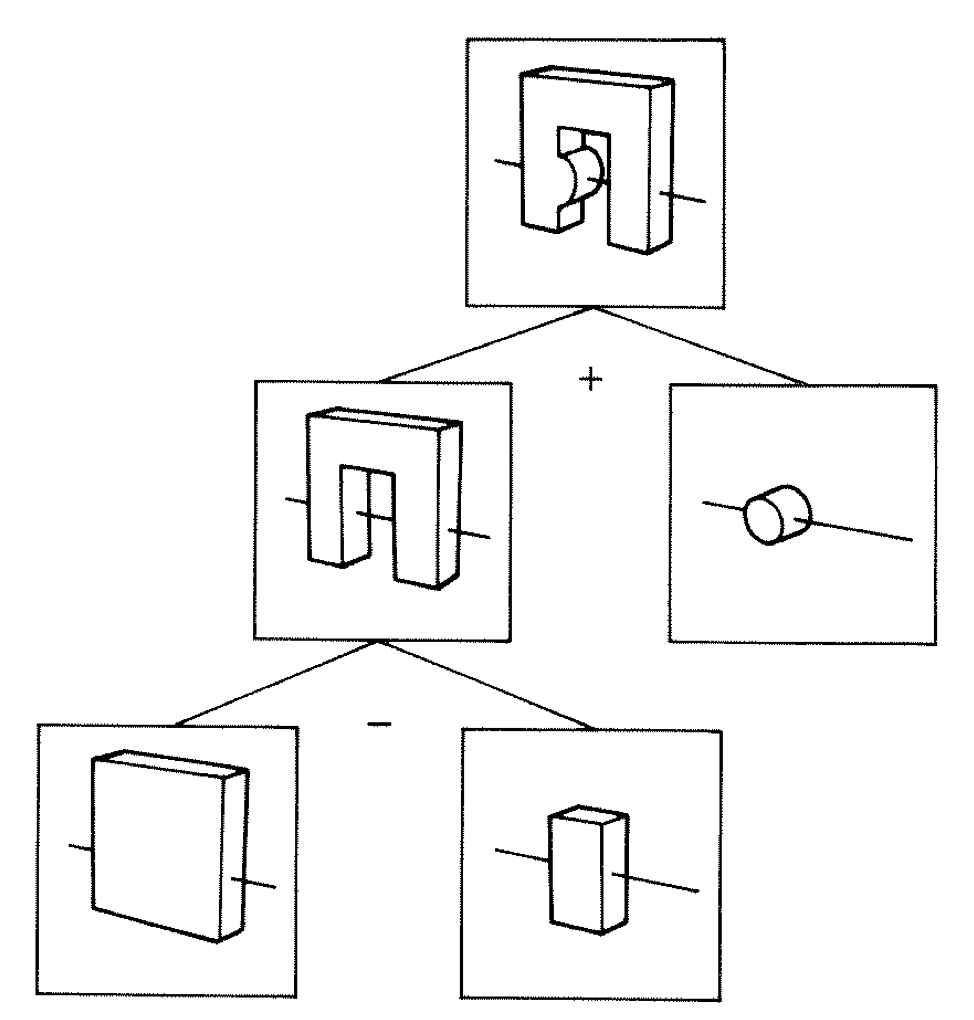
List-node avoids deep CSG trees
Problematic deep CSG tree without list-node
+------------------------------------------+
| |
| |
| U |
| / \ |
| / \ |
| / S |
| U / \ |
| / \ I J |
| U H |
| / \ |
| U G |
| / \ |
| U F |
| / \ |
| U E |
| / \ |
| U D |
| / \ |
| U C |
| / \ |
| A B |
| |
+------------------------------------------+
U : Union
S : Subtraction
A-J : Tubs (cylinder) primitive
Simple G4MultiUnion is translated to Opticks list-node
Pure Optical TorchGenstep scan : 1M to 100M photons
TEST=medium_scan ~/opticks/cxs_min.sh
Generate optical only events with 1M->100M photons starting from CD center,
gather and save only Hits.
OPTICKS_RUNNING_MODE=SRM_TORCH ## "Torch" running enables num_photon scan
OPTICKS_NUM_PHOTON=M1,10,20,30,40,50,60,70,80,90,100
OPTICKS_NUM_EVENT=11
OPTICKS_EVENT_MODE=Hit
- uses CSGOptiXSMTest executable (no Geant4 dependency, avoids ~150s of initialization time)
- load and upload geometry in ~2s
Compare simulation scans on two Dell Precision Workstations:
| GPU (VRAM) |
Arch |
GPU Release |
CUDA(RT) Cores |
RTX Gen |
Driver |
CUDA |
OptiX |
|---|
| NVIDIA TITAN RTX(24G) |
Turing |
Dec 2018 |
4,608(72) |
1st |
515.43 |
11.7 |
7.5 |
| NVIDIA RTX 5000(32G) |
Ada |
Aug 2023 |
12,800(100) |
3rd |
550.76 |
12.4 |
8.0 |
- max launch size : 24/32/48G VRAM ~200/266/400M photons
ALL1_scatter_10M_photon_22pc_hit_alt.png
- 4.5M hits from 20M photon TorchGenstep, 4.4(1.1) seconds
- with: NVIDIA TITAN RTX(NVIDIA RTX 5000 Ada) 1st(3rd) gen RTX
AB_Substamp_ALL_Etime_vs_Photon_rtx_gen1_gen3.png
Event Time(s) vs PH(M)
| PH(M) |
G1 |
G3 |
G1/G3 |
|---|
| 1 |
0.47 |
0.14 |
3.28 |
| 10 |
0.44 |
0.13 |
3.48 |
| 20 |
4.39 |
1.10 |
3.99 |
| 30 |
8.87 |
2.26 |
3.93 |
| 40 |
13.29 |
3.38 |
3.93 |
| 50 |
18.13 |
4.49 |
4.03 |
| 60 |
22.64 |
5.70 |
3.97 |
| 70 |
27.31 |
6.78 |
4.03 |
| 80 |
32.24 |
7.99 |
4.03 |
| 90 |
37.92 |
9.33 |
4.06 |
| 100 |
41.93 |
10.42 |
4.03 |
Optical simulation 4x faster 1st->3rd gen RTX, (3rd gen, Ada : 100M photons simulated in 10 seconds) [TMM PMT model]
How much parallelized speedup actually useful to overall speedup?
optical photon simulation, P ~ 99% of CPU time
- => limit on overall speedup S(n) is 100x
- even with parallel speedup factor >> 1000x
Traditional simulation use:
- speedup beyond 1000x not needed
amdahl_p_sensitive.png
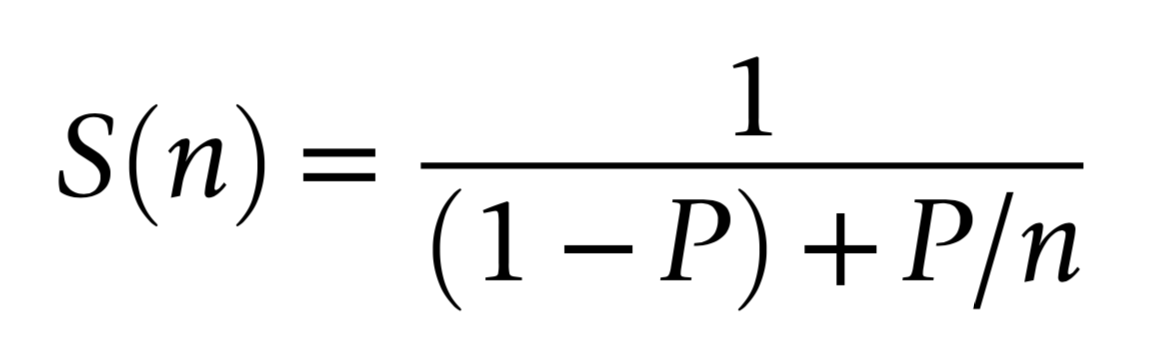
Summary and Links
Opticks : state-of-the-art GPU ray traced optical simulation integrated with Geant4,
with automated geometry translation into GPU optimized form.
- NVIDIA Ray Trace Performance continues rapid progress (2x each gen., every ~2 yrs)
- any simulation limited by optical photons can benefit from Opticks
- more photon limited -> more overall speedup (99% -> ~90x)
Acknowledgements
- Opticks users
- ~38 members of forum : https://groups.io/g/opticks
- many thanks to active bug reporting users
- (especially from JUNO, LZ, LHAASO, LHCb-RICH, DUNE, NEXT-CRAB0)
- JUNO Collaboration
- Tao Lin, Yuxiang Hu, ... (+ many more : changing geometry and physics models)
- forced Opticks to continuously improve
- Geant4 collaboration
- especially Hans Wentzel, Fermilab Geant4 group, early adopter of Opticks
- guest invites to Okinawa, Wollongong meetings
- Dark Matter Search Community (XENON,LZ,DARWIN,..) : DANCE invite 2019
- Many NVIDIA Engineers:
- NVIDIA GPU Technology Conferences (San Jose, Suzhou)
- seven dedicated meetings in 2021 : migrating to OptiX 7 API
- UK GPU Hackathon 2022
Divider
Opticks History, early Chroma use, triangles...
Outline (2) : Review Opticks History
- Opticks : Decade of GPU ray trace optical photon simulation
- Early : pure triangles, Chroma, instancing
- Opticks pre-History (2014) : Chroma investigations for DayaBay
- G4DAE : DYB pool bottom, Chroma raycast + OpenGL render
- Daya Bay Chroma Photon Propagation (1)
- Opticks History (2015) : Chroma + G4DAE -> NVIDIA OptiX + "Opticks"
- Opticks History (2016) : Handling Huge Geometry (JUNO) with instancing
- Transition from triangles to analytic CSG
- Opticks History (2016) : Triangulated Geometry Problems
- Opticks History (2016) : Analytic PMT (12 parts, not 2928 triangles)
- Daya Bay Opticks Propagation : Triangulated + Analytic PMT
- Opticks History (2017) GPU Geometry starts from ray-primitive intersection
- Torus : much more difficult/expensive than other primitives
- Constructive Solid Geometry (CSG) : Which intersect ?
- Opticks History (2017) : Developed GPU CSG Impl. based on short note with the idea
- Ray intersection with general CSG binary trees, on GPU
- CSG Complete Binary Tree Serialization -> simplifies GPU side
- Opticks Analytic Daya Bay Near Site, GPU Raytrace
- Pure analytic CSG JUNO geometry
- Approximate triangulated JUNO geometry
- Validation
- Validation of Opticks Simulation by Comparison with Geant4
- Optical Simulation Comparison : Statistical OR Direct
- Full photon step point details enable debug, here from input photons
- nEXO + Opticks ?
- nEXO + Opticks : Typical Issues
- Some Opticks users
- NEXT-CRAB0 Prototype + Opticks
- CaTS: Integration of Geant4 and Opticks
- LHCb-RICH + Opticks
- LZ + Opticks (Sam Eriksen, University of Bristol)
- Summary and Links
Opticks : Decade of GPU ray trace optical photon simulation
- 2014 : fork Chroma for DayaBay Optical sim
- develop G4DAE : exports Geant4 geom. => triangles
- 2015 : drop Chroma for NVIDIA OptiX : 50x faster RT
- adopt the name "Opticks" in honour of Isaac
- 2016 : triangulated geometry problems
- PMT impossible to match with G4 : "disco ball"
- G4Polyhedron => cleaved mesh ~25/250 DYB solids
- "manual" analytic PMT, rest triangles
- start move away from tri.
- 2017 : impl. general analytic CSG intersection, instancing
- => fully analytic geometry, can precisely match Geant4
- 2018 : consolidation/automation
- Optical Physics implemented on OptiX 6 [OOPS]
- Geant4 -> Opticks CSG auto-translation
- NVIDIA: "world first ray tracing GPU" (RTX)
- adapt Opticks to work with RTX
- 2019 : NVIDIA bombshell : entirely new OptiX 7.0.0 API
- much of previous two years work out the window
Attempt to use mainly triangulated detector geometry : eventually led nowhere
Opticks pre-History (2014) : Chroma investigations for DayaBay
CAVEAT : I LAST USED CHROMA IN 2015
Chroma : Disadvantages
- No use of ray trace engine, eg NVIDIA OptiX
- No use of dedicated ray trace hardware RT cores (RTX)
- BYOB : rolls own BVH acceleration structure
- expert tuning work needed for new GPU arch ?
Chroma : Fundamental Problem, triangles only
- best available polygonization, G4Polyhedron
- some solids (eg G4Polycone) yield "cleaved" meshes
- viz. bug for Geant4, broken geometry for Chroma
- OpenMesh surgery possible, but not automatic
Geant4 analytic -> Triangles ? Problematic
- developed "G4DAE" Geant4 exporter of 3D DAE files
- added DAE import to my Chroma fork
- 2014 : bought macbook pro (NVIDIA Geforce 750M GPU)
chroma_camera_raycast
(g4daeview.py) Chroma Raycast of Daya Bay geometry (3x3 CUDA kernel launches, 1.8s for 1.23M pixels, Geforce 750M GPU)
Split launch + use CUDA/OpenGL interop => enable mobile GPU render
G4DAE : DYB pool bottom, Chroma raycast
- (g4daeview.py) Chroma raycast render of triangulated geometry
- approximate geometry apparent
G4DAE : DYB pool bottom, OpenGL render
(g4daeview.py) OpenGL rasterized render of triangulated geometry
Daya Bay Chroma Photon Propagation (1)
(g4daeview.py) Chroma GPU photon propagation at 12 nanoseconds. The photons are generated by Geant4
simulation of a 100 GeV muon travelling from right to left.
Photon colors indicate reemission (green), absorption(red),
specular reflection (magenta), scattering(blue), no history (white).
Opticks History (2015) : Chroma + G4DAE -> NVIDIA OptiX + "Opticks"
Why switch to NVIDIA OptiX ?
- 50x faster DYB raycast
- OptiX 5 : transparent multi-GPU with no effort
- NVIDIA supported package
- NVIDIA expertise on keeping GPUs busy
- C++ impl. for Geant4 integration (Chroma:python/numpy/pycuda)
Initially used tri. with OptiX, later analytic CSG
"Opticks" started as synthesis:
- Chroma : high level propagation loop structure
- Geant4 : simulation details
- Graphics : performance techniques
Package name "Opticks", taken from world changing publication:
- Sir Isaac Newton FRS "Opticks: or, A Treatise of the Reflexions, Refractions, Inflexions and Colours of Light."
GGeoView
(GGeoView) Cerenkov photons from an 100 GeV muon travelling from right to left across Dayabay AD.
Primaries are simulated by Geant4, Cerenkov "steps" of the primaries are transferred to the GPU.
The dots represent OptiX calculated first intersections of GPU generated photons with colors
corresponding to material boundaries: (red) GdDopedLS/Acrylic
(green) LiquidScintillator/Acrylic, (blue) Acrylic/LiquidScintillator,
(white) IwsWater:UnstStainlessSteel, (grey) others.
The red lines represent the positions and directions of the "steps" with an
arbitrary scaling for visibility.
Opticks History : Handling Huge Geometry (eg JUNO)
Opticks History (2016) : Handling Huge Geometry (JUNO) with instancing
Instancing in OptiX and OpenGL avoids repetition of geometry data on GPU for repeated elements (eg PMTs).
[Image is composite of OpenGL rasterized event representation and OptiX raytraced triangulated geom]
Opticks History (2016) : Triangulated Geometry Problems
- G4Polyhedron tesselation of union solids -> cleaved mesh
- visualization bug for Geant4, broken geometry if rely on tesselation for simulation
- manifests as reversed normals causing material mis-assignment
- ~10% of Daya Bay solid tesselations had issues : fixed some with OpenMesh surgery : unable to automate
- even when not broken, usually approximate geometry : cannot precisely match Geant4
- PMT "Disco Ball" effect (smoothed vertex normals can reduce this)
triangulated geometry : not practical for general simulation, but very useful for fast visualization


Opticks History (2016) : Analytic PMT (12 parts, not 2928 triangles)
NVIDIA OptiX provided no intersect (just accel. intersect)
- need first principals intersection code, solving polynomials
- started with PMT specific intersection code
Partition PMT at constituent joins (semi-manually)
Daya Bay Opticks Propagation : Triangulated + Analytic PMT
Daya Bay Opticks Propagation : Triangulated geometry with Analytic PMT
[composite OptiX raytrace geometry + OpenGL rasterized Cerenkov photons]
Opticks (2017) : GPU Geometry starts from ray-primitive intersection
- 3D parametric ray : ray(x,y,z;t) = rayOrigin + t * rayDirection
- implicit equation of primitive : f(x,y,z) = 0
- -> polynomial in t , roots: t > t_min -> intersection positions + surface normals
Torus : much more difficult/expensive than other primitives
3D parametric ray : ray(x,y,z;t) = rayOrigin + t * rayDirection
- ray-torus intersection -> solve quartic polynomial in t
- A t^4 + B t^3 + C t^2 + D t + E = 0
High order equation
- very large difference between coefficients
- varying ray -> wide range of very coefficients
- numerically problematic, requires double precision
- several mathematical approaches used, work in progress
Best Solution : replace torus
- eg model PMT neck with hyperboloid, not cylinder-torus
Constructive Solid Geometry (CSG) : Which intersect ?
Simple by construction definition, implicit geometry.
- A, B implicit primitive solids
- A + B : union (OR)
- A * B : intersection (AND)
- A - B : difference (AND NOT)
- !B : complement (NOT) (inside <-> outside)
CSG expressions
- non-unique: A - B == A * !B
- represented by binary tree, primitives at leaves
3D Parametric Ray : ray(t) = r0 + t rDir
Ray Geometry Intersection
- primitive : find t roots of implicit eqn
- composite : pick primitive intersect, depending on CSG tree
How to pick exactly ?
2017 : Developed GPU CSG Impl. based on short note with the idea
- "Ray Tracing CSG Objects Using Single Hit Intersections", Andrew Kensler (2006) 3 page note
- http://xrt.wikidot.com/doc:csg corrections from author of XRT Renderer

Ray intersection with general CSG binary trees, on GPU
Pick between pairs of nearest intersects, eg:
| UNION tA < tB |
Enter B |
Exit B |
Miss B |
|---|
| Enter A |
ReturnA |
LoopA |
ReturnA |
| Exit A |
ReturnA |
ReturnB |
ReturnA |
| Miss A |
ReturnB |
ReturnB |
ReturnMiss |
- Nearest hit intersect algorithm [1] avoids state
- sometimes Loop : advance t_min , re-intersect both
- classification shows if inside/outside
- Evaluative [2] implementation emulates recursion:
- recursion not allowed in OptiX intersect programs
- bit twiddle traversal of complete binary tree
- stacks of postorder slices and intersects
- Identical geometry to Geant4
- solving the same polynomials
- near perfect intersection match
- [1] Ray Tracing CSG Objects Using Single Hit Intersections, Andrew Kensler (2006)
- with corrections by author of XRT Raytracer http://xrt.wikidot.com/doc:csg
- [2] https://bitbucket.org/simoncblyth/opticks/src/tip/optixrap/cu/csg_intersect_boolean.h
- Similar to binary expression tree evaluation using postorder traverse.
CSG Complete Binary Tree Serialization -> simplifies GPU side
Geant4 solid -> CSG binary tree (leaf primitives, non-leaf operators, 4x4 transforms on any node)
Serialize to complete binary tree buffer:
- no need to deserialize, no child/parent pointers
- bit twiddling navigation avoids recursion
- simple approach profits from small size of binary trees
- BUT: very inefficient when unbalanced
Height 3 complete binary tree with level order indices:
depth elevation
1 0 3
10 11 1 2
100 101 110 111 2 1
1000 1001 1010 1011 1100 1101 1110 1111 3 0
postorder_next(i,elevation) = i & 1 ? i >> 1 : (i << elevation) + (1 << elevation) ; // from pattern of bits
Postorder tree traverse visits all nodes, starting from leftmost, such that children
are visited prior to their parents.
Opticks Analytic Daya Bay Near Site, GPU Raytrace
Pure analytic CSG Daya Bay near geometry, auto-converted from Geant4 to Opticks GPU geometry,
NVIDIA OptiX GPU raytrace render [no triangles]
j1808_top_rtx
Pure analytic CSG JUNO geometry, auto-converted from Geant4 to Opticks GPU geometry,
NVIDIA OptiX GPU raytrace render [no triangles] (GGeoView)
j1808_top_ogl
Approximate triangulated JUNO geometry [note impingement of torus guide tube and acrylic "sphere"], OpenGL rasterized render (GGeoView)
Validation of Opticks Simulation(A) by Comparison with Geant4 Sim. (B)
A and B always same photon counts (due to gensteps)
- direct comparison when simulations are random aligned
- when not aligned : statistical Chi2 history comparison
- compare history frequencies, Chi2 points to issues
Primary Issue : double vs float, also:
- geometry bugs : overlaps, coincident faces
- grazing incidence, edge skimmers
After debugged : fraction of percent diffs
scan-pf-check-GUI-TO-SC-BT5-SD
Optical Simulation Comparison : Statistical OR Direct
Statistical Chi-squared comparison of photon history occurence between two simulations
- powerful metric to find discrepancies between simulations (eg from near-degenerate geometry)
c2sum/c2n:c2per(C2CUT) 280.88/188:1.494 (30)
np.c_[siq,_quo,siq,sabo2,sc2,sabo1][0:25] ## A-B history frequency chi2 comparison
0 TO BT BT BT BT SD 33322 33343 0.0066 1 2
1 TO BT BT BT BT SA 28160 28070 0.1441 8 0
2 TO BT BT BT BT BT SR SA 6270 6268 0.0003 10363 10565
3 TO BT BT BT BT BT SA 4552 4649 1.0226 8398 8433
4 TO BT BT BT BT BT SR BR SR SA 1154 1186 0.4376 21156 21014
5 TO BT BT BT BT BT SR BR SA 923 989 2.2782 20241 20201
6 TO BT BT BT BT BR BT BT BT BT BT BT AB 946 958 0.0756 10389 8432
7 TO BT BT BT BT BT SR SR SA 901 942 0.9121 10399 10410
8 TO BT BT AB 878 895 0.1630 26 102
9 TO BT BT BT BT BT SR BT BT BT BT BT BT BT AB 615 635 0.3200 20974 22027
10 TO BT BT BT BT BR BT BT BT BT AB 571 601 0.7679 8459 9208
11 TO BT BT BT BT BR BT BT BT BT BT BT BT BT SA 533 537 0.0150 7312 7299
12 TO BT BT BT BT BR BT BT BT BT BT BT BT BT BT BT BT BT SD 503 396 12.7353 12018 11465
13 TO BT BT BT BT BR BT BT BT BT BT BT BT BT SD 480 497 0.2958 7974 7967
14 TO BT BT BT BT BR BT BT BT BT BT BT BT BT BT BT BT BT SA 412 411 0.0012 11467 11471
15 TO BT BT BT BT BT SR SR SR SA 383 396 0.2169 10362 10368
When causes of discrepancy cannot be identified statistically
- use common input photons + aligned random consumption between simulations
- enable direct photon-to-photon comparison of simulations : reveals precisely where simulations diverge
Comparison of two independent optical simulation implementations : ideal way find issues
B_V1J008_N1_ip_MOI_Hama:0:1000_yy_frame_close.png
Full photon step point details enable debug, here from input photons
Green : start position (100k input photons)
Red : end position, Cyan : other position
nEXO + Opticks : Typical Issues
Opticks geometry translation is general, but often work needed to:
- support all your solids
- be performant with all your solids
- deep CSG trees problematic
- use geometry scanning to find slow solids
- avoid problems of coincident surfaces
- float precision CSG more susceptible than G4
- detailed validation required
- get instance "factorized" optimally
Potential to make your simulation unlimited by optical photons
Some Opticks users
- NEXT-CRAB0 Prototype (Ilker Parmaksiz)
- CaTS (Hans Wentzel, Fermilab Geant4 Group)
- LHCb-RICH (Sajan Easo + Manchester Group)
- LZ (Sam Eriksen + ..)
While Opticks changing rapidly...
- did not seek users much, some brave ones turned up anyhow
- many thanks to active bug reporting users
More active users very welcome,
- necessary for Opticks to mature
- users still need to be brave + must be willing to read the code
Ilker Parmaksiz, NEXT-CRAB0 Prototype
New active bug reporting Opticks user : Ilker Parmaksiz
- careful comparison : Data, Geant4, Opticks
- Opticks 181x over Geant4
CaTS: Integration of Geant4 and Opticks
lhcb_rich1_epjc_001.png
LZ + Opticks (Sam Eriksen, University of Bristol)
had contacts with ~5 LZ people
Summary and Links
Opticks : state-of-the-art GPU ray traced optical simulation integrated with Geant4,
with automated geometry translation into GPU optimized form.
- NVIDIA Ray Trace Performance continues rapid progress (2x each gen., every ~2 yrs)
- any simulation limited by optical photons can benefit from Opticks
- more photon limited -> more overall speedup (99% -> ~90x)