Opticks : Optical Photon Simulation via GPU Ray Tracing from NVIDIA OptiX
Opticks : Optical Photon Simulation via GPU Ray Tracing from NVIDIA® OptiX™
Open source, https://bitbucket.org/simoncblyth/opticks
Simon C Blyth, IHEP, CAS — Zhejiang University, Hangzhou — 27 February 2024
Outline

- Optical Photon Simulation : Context and Problem
- JUNO Optical Photon Simulation Problem...
- Optical photons limit many simulations => lots of interest in Opticks
- Assistance : Geant4 Collab. + Dark Matter Search Community + NVIDIA
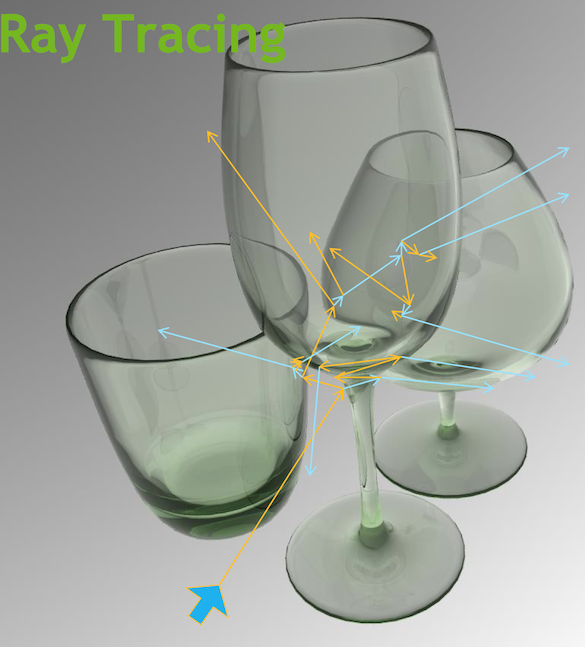
- Optical Photon Simulation ≈ Ray Traced Image Rendering
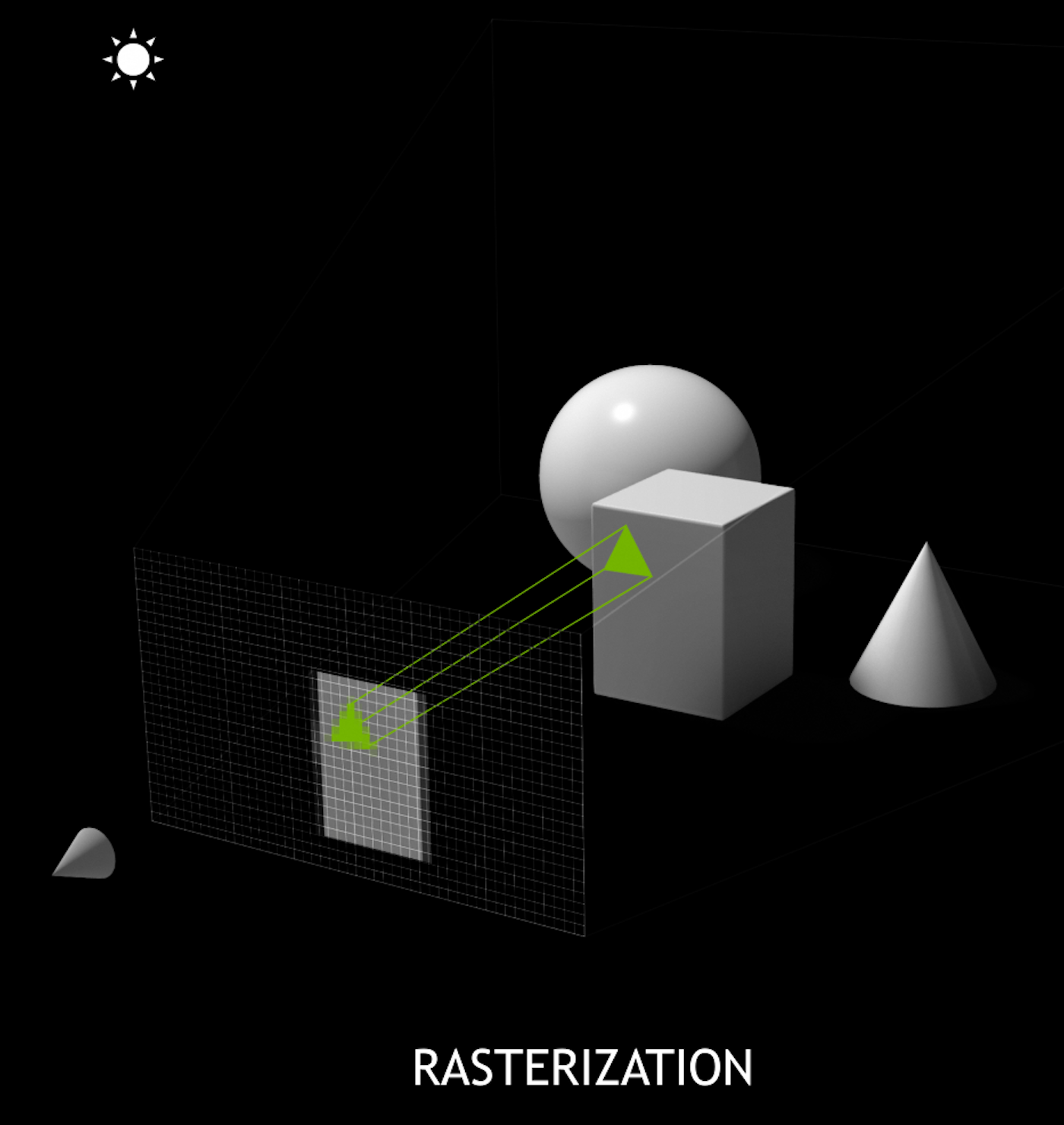
- Rasterization vs Ray Tracing
- Monte Carlo Path tracing in (movie) production
- Fundamental "Rendering Equation" of Computer Graphics (Kajiya 1986)
- Neumann Series Solution of Rendering Equation, Samples per pixel
- Optical Simulation : Computer Graphics vs Physics
- NVIDIA Tools to create Solution
- SIGRAPH 2018
- NVIDIA Ada Lovelace : 3rd Generation RTX, RT Cores in Data-Center
- NVIDIA OptiX Ray Tracing Engine
- NVIDIA OptiX 7 : Entirely new thin API, BVH Acceleration Structure
- Opticks : Introduction + Full Re-implementation
- Geant4 + Opticks Hybrid Workflow : External Optical Photon Simulation
- Geometry Model Translation : Geant4 => CSGFoundry => NVIDIA OptiX 7
- Ray trace render performance scanning
- QUDARap : CUDA Optical Simulation Implementation
- Validation
- Opticks New Features : Multi-Layer Thin Film (A,R,T) Calc using TMM (Custom4 Package)
JUNO Optical Photon Simulation Problem...
Optical photons limit many simulations => lots of interest in Opticks
| EXPT |
Reactor neutrino |
| Daya Bay |
neutrino oscillations |
| JUNO |
mass heirarchy + oscillations => NVIDIA CN Contacts |
| |
Long baseline neutrino beam |
| DUNE |
FermiLab->Sanford, LAr TPC, => Assistance from Fermilab Geant4 Group |
| |
Neutrinoless double beta decay, dark matter, other search |
| LZ |
LUX-ZEPLIN dark matter experiment, Sandford => NVIDIA US Contacts |
| LEGEND |
Large Enriched Germanium Experiment, Gran Sasso/SNOLAB |
| SABRE |
dark matter direct-detection, Australia |
| AMoRE |
Mo-based Rare process Experiment, S.Korea |
| nEXO |
next Enriched Xenon Observatory, LLNL |
| |
Neutrino telescope |
| KM3Net |
Cubic Kilometre Neutrino Telescope, Mediterranean |
| IceCube |
IceCube Neutrino Observatory, South Pole |
| |
Air shower : gamma-ray and cosmic-ray observatory |
| LHAASO |
Large High Altitude Air Shower Observatory, Sichuan |
| |
Accelerator |
| LHCb-RICH |
LHCb ring imaging Cherenkov sub-detector, CERN => NVIDIA EU Contacts |
Optical Photon Simulation ≈ Ray Traced Image Rendering
- simulation
- photon parameters at sensors (PMTs)
- rendering
- pixel values at image plane
Much in common : geometry, light sources, optical physics
- both limited by ray geometry intersection, aka ray tracing
Many Applications of ray tracing :
- advertising, design, architecture, films, games,...
- -> huge efforts to improve hw+sw over 30 yrs
Rasterization vs Ray-tracing
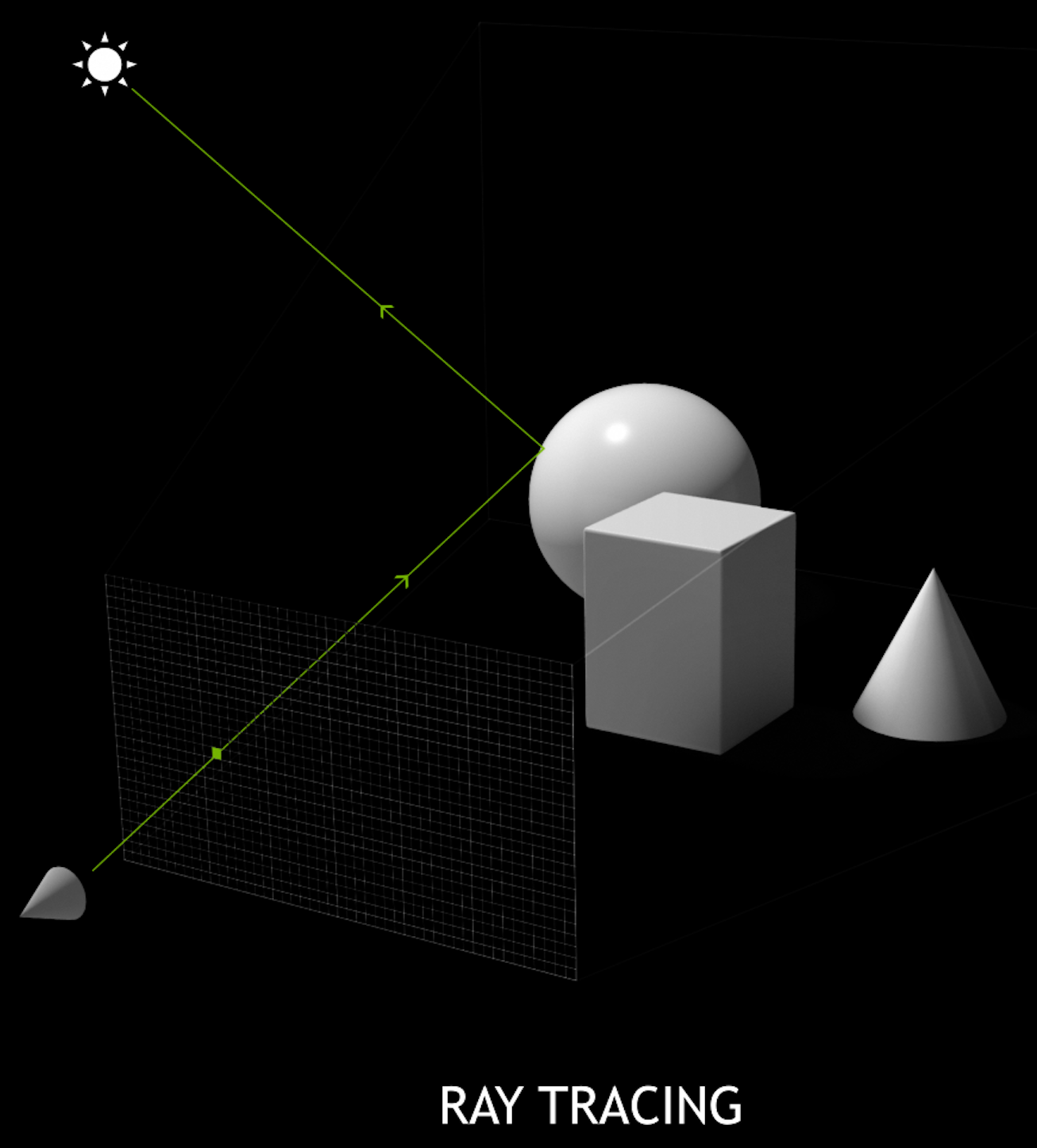
Path Tracing in Production 1
Path Tracing in Production 2
The Rendering Equation 1
The Rendering Equation 2
Samples per Pixel 1
Samples per Pixel 2
Optical Simulation : Computer Graphics vs Physics
| CG Rendering "Simulation" |
Particle Physics Simulation |
|---|
| simulates: image formation, vision |
simulates photons: generation, propagation, detection |
| (red, green, blue) |
wavelength range eg 400-700 nm |
| ignore polarization |
polarization vector propagated throughout |
| participating media: clouds,fog,fire [1] |
bulk scattering: Rayleigh, MIE |
| human exposure times |
nanosecond time scales |
| equilibrium assumption |
transient phenomena |
| ignores light speed, time |
arrival time crucial, speed of light : 30 cm/ns |
- handling of time is the crucial difference
Despite differences many techniques+hardware+software directly applicable to physics eg:
- GPU accelerated ray tracing (NVIDIA OptiX)
- GPU accelerated property interpolation via textures (NVIDIA CUDA)
- GPU acceleration structures (NVIDIA BVH)
Potentially Useful CG techniques for "billion photon simulations"
- irradiance caching, photon mapping, progressive photon mapping
[1] search for: "Volumetric Rendering Equation"
SIGGRAPH_2018_Announcing_Worlds_First_Ray_Tracing_GPU
NVIDIA Ada : 3rd Generation RTX
- RT Core : ray trace dedicated GPU hardware
- NVIDIA GeForce RTX 4090 (2022)
- 16,384 CUDA Cores, 24GB VRAM, USD 1599
- Continued large ray tracing improvements:
- Ada ~2x ray trace over Ampere (2020), 4x with DLSS 3
- Ampere ~2x ray trace over Turing (2018)
- DLSS : Deep Learning Super Sampling
- AI upsampling, not applicable to optical simulation
Hardware accelerated Ray tracing (RT Cores) in the Data Center
NVIDIA L4 Tensor Core GPU (Released 2023/03)
- Ada Lovelace GPU architecture
- universal accelerator for graphics and AI workloads
- small form-factor, easy to integrate, power efficient
- PCIe Gen4 x16 slot without extra power
- Google Cloud adopted for G2 VMs, successor to NVIDIA T4
- NVIDIA L4 likely to become a very popular GPU
NVIDIA L4 Tensor Core GPU (Data Center, low profile+power)
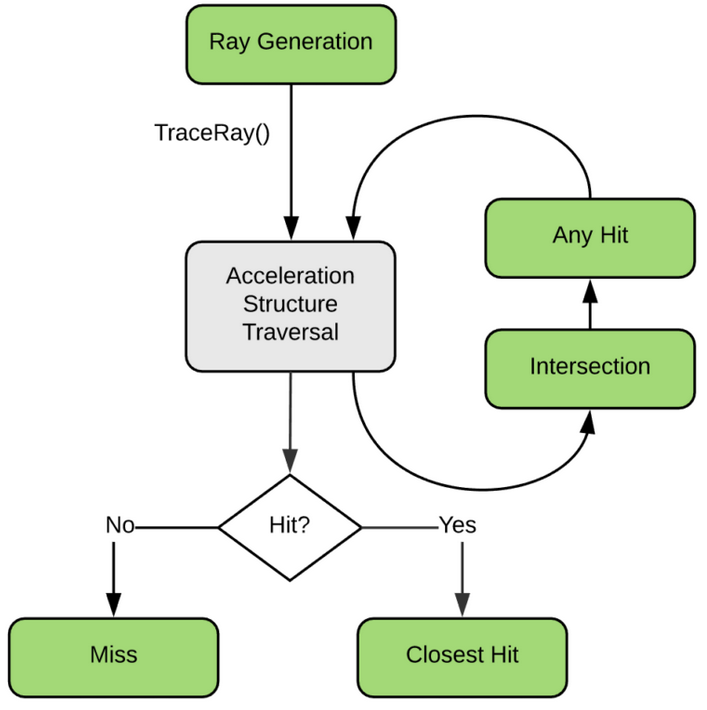
NVIDIA® OptiX™ Ray Tracing Engine -- Accessible GPU Ray Tracing
OptiX makes GPU ray tracing accessible
- Programmable GPU-accelerated Ray-Tracing Pipeline
- Single-ray shader programming model using CUDA
- ray tracing acceleration using RT Cores (RTX GPUs)
- "...free to use within any application..."
OptiX features
- acceleration structure creation + traversal (eg BVH)
- instanced sharing of geometry + acceleration structures
- compiler optimized for GPU ray tracing
https://developer.nvidia.com/rtx/ray-tracing/optix
User provides (Green):
- ray generation
- geometry bounding boxes
- intersect functions
- instance transforms
Spatial Index Acceleration Structure
NVIDIA OptiX 7 : Entirely new thin API => Full Opticks Re-implementation
NVIDIA OptiX 6->7 : drastically slimmed down
- low-level CUDA-centric thin API (Vulkan-ized)
- headers only (no library, impl in Driver)
- Minimal host state, All host functions are thread-safe
- GPU launches : explicit, asynchronous (CUDA streams)
- near perfect scaling to 4 GPUs, for free
- Shared CPU/GPU geometry context
- GPU memory management
- Multi-GPU support
Advantages of 6->7 transition
- More control/flexibility over everything
- Keep pace with state-of-the-art GPU ray tracing
- Fully benefit from current + future GPUs : RT cores, RTX
BUT: demanded full re-implementation of Opticks
Geant4 + Opticks + NVIDIA OptiX 7 : Hybrid Workflow
| https://bitbucket.org/simoncblyth/opticks |
Opticks API : split according to dependency -- Optical photons are GPU "resident", only hits need to be copied to CPU memory
Geant4 + Opticks + NVIDIA OptiX 7 : Hybrid Workflow 2
How to Make Effective Use of GPUs ? Parallel / Simple / Uncoupled
- Abundant parallelism
- many thousands of tasks (ideally millions)
- Low register usage : otherwise limits concurrent threads
- simple kernels, avoid branching
- Little/No Synchronization
- avoid waiting, avoid complex code/debugging
- Minimize CPU<->GPU copies
- reuse GPU buffers across multiple CUDA launches

How Many Threads to Launch ?
- can (and should) launch many millions of threads
- mince problems as finely as feasible
- maximum thread launch size : so large its irrelevant
- maximum threads inflight : #SM*2048 = 80*2048 ~ 160k
- best latency hiding when launch > ~10x this ~ 1M
Understanding Throughput-oriented Architectures
https://cacm.acm.org/magazines/2010/11/100622-understanding-throughput-oriented-architectures/fulltext
NVIDIA Titan V: 80 SM, 5120 CUDA cores
Primary Packages and Structs Of Re-Implemented Opticks
- SysRap : many small CPU/GPU headers
- stree.h,snode.h : geometry base types
- sctx.h sphoton.h : event base types
- NP.hh : serialization into NumPy .npy format files
- QUDARap
- QSim : optical photon simulation steering
- QScint,QCerenkov,QProp,... : modular CUDA implementation
- U4
- U4Tree : convert geometry into stree.h
- U4 : collect gensteps, return hits
- CSG
- CSGFoundry/CSGSolid/CSGPrim/CSGNode geometry model
- csg_intersect_tree.h csg_intersect_node.h csg_intersect_leaf.h : CPU/GPU intersection functions
- CSGOptiX
- CSGOptiX.h : manage geometry convert from CSG to OptiX 7 IAS GAS, pipeline creation
- CSGOptiX7.cu : compiled into ptx that becomes OptiX 7 pipeline
- includes QUDARap headers for simulation
- includes csg_intersect_tree.h,.. headers for CSG intersection
- G4CX
- G4CXOpticks : Top level Geant4 geometry interface
Geometry Model Translation : Geant4 => CSGFoundry => NVIDIA OptiX 7
Geant4 Geometry Model (JUNO: 300k PV, deep hierarchy)
| PV |
G4VPhysicalVolume |
placed, refs LV |
| LV |
G4LogicalVolume |
unplaced, refs SO |
| SO |
G4VSolid,G4BooleanSolid |
binary tree of SO "nodes" |
Opticks CSGFoundry Geometry Model (index references)
| struct |
Notes |
Geant4 Equivalent |
|---|
| CSGFoundry |
vectors of the below, easily serialized + uploaded + used on GPU |
None |
| qat4 |
4x4 transform refs CSGSolid using "spare" 4th column (becomes IAS) |
Transforms ref from PV |
| CSGSolid |
refs sequence of CSGPrim |
Grouped Vols + Remainder |
| CSGPrim |
bbox, refs sequence of CSGNode, root of CSG Tree of nodes |
root G4VSolid |
| CSGNode |
CSG node parameters (JUNO: ~23k CSGNode) |
node G4VSolid |
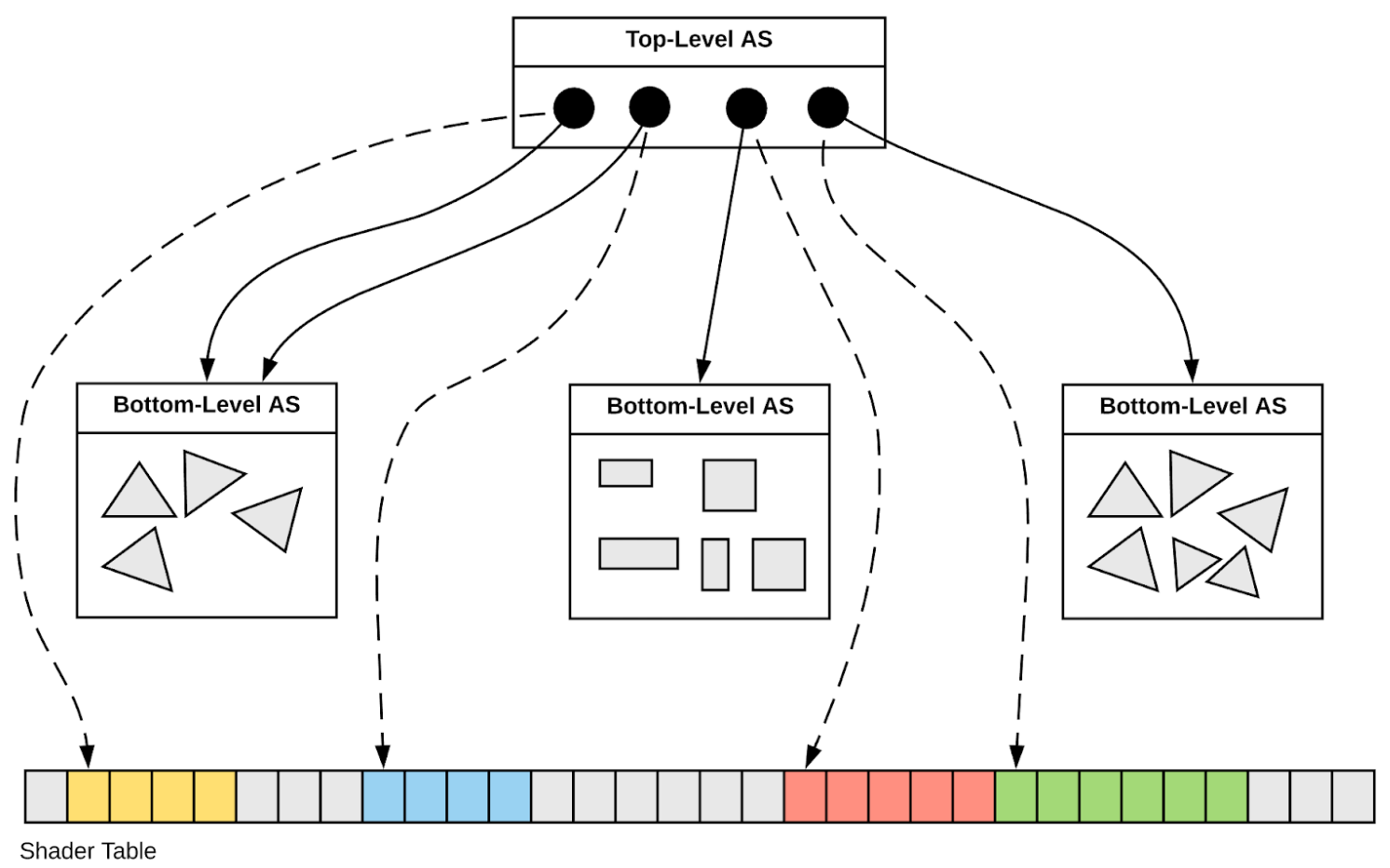
NVIDIA OptiX 7 Geometry Acceleration Structures (JUNO: 1 IAS + 10 GAS, 2-level hierarchy)
| IAS |
Instance Acceleration Structures |
JUNO: 1 IAS created from vector of ~50k qat4 (JUNO) |
| GAS |
Geometry Acceleration Structures |
JUNO: 10 GAS created from 10 CSGSolid (which refs CSGPrim,CSGNode ) |
JUNO : Geant4 ~300k volumes "factorized" into 1 OptiX IAS referencing ~10 GAS
Opticks : GPU Geometry starts from ray-primitive intersection
- 3D parametric ray : ray(x,y,z;t) = rayOrigin + t * rayDirection
- implicit equation of primitive : f(x,y,z) = 0
- -> polynomial in t , roots: t > t_min -> intersection positions + surface normals
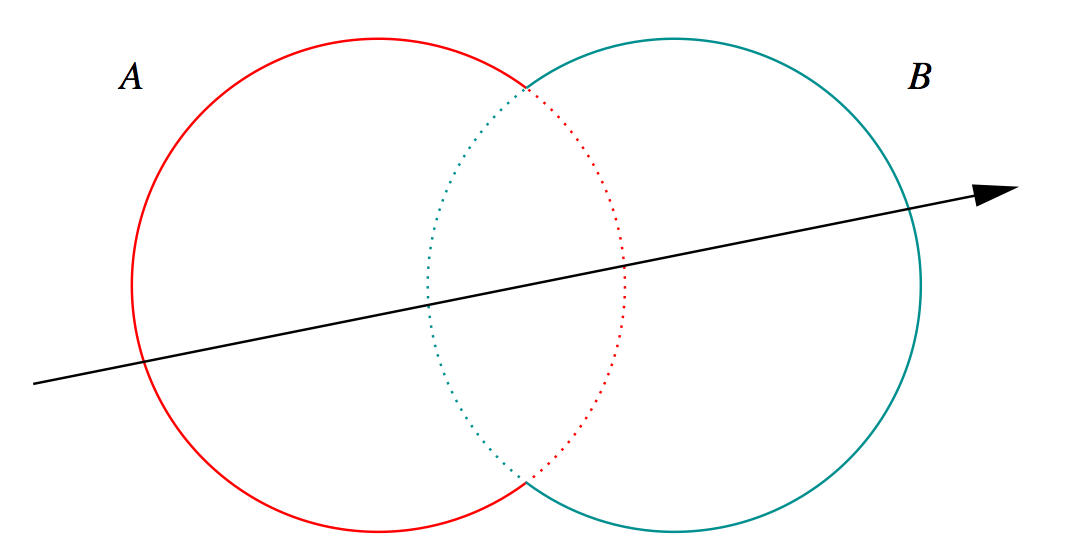
Ray intersection with general CSG binary trees, on GPU
Pick between pairs of nearest intersects, eg:
| UNION tA < tB |
Enter B |
Exit B |
Miss B |
|---|
| Enter A |
ReturnA |
LoopA |
ReturnA |
| Exit A |
ReturnA |
ReturnB |
ReturnA |
| Miss A |
ReturnB |
ReturnB |
ReturnMiss |
- Nearest hit intersect algorithm [1] avoids state
- sometimes Loop : advance t_min , re-intersect both
- classification shows if inside/outside
- Evaluative [2] implementation emulates recursion:
- recursion not allowed in OptiX intersect programs
- bit twiddle traversal of complete binary tree
- stacks of postorder slices and intersects
- Identical geometry to Geant4
- solving the same polynomials
- near perfect intersection match
- [1] Ray Tracing CSG Objects Using Single Hit Intersections, Andrew Kensler (2006)
- with corrections by author of XRT Raytracer http://xrt.wikidot.com/doc:csg
- [2] https://bitbucket.org/simoncblyth/opticks/src/tip/optixrap/cu/csg_intersect_boolean.h
- Similar to binary expression tree evaluation using postorder traverse.
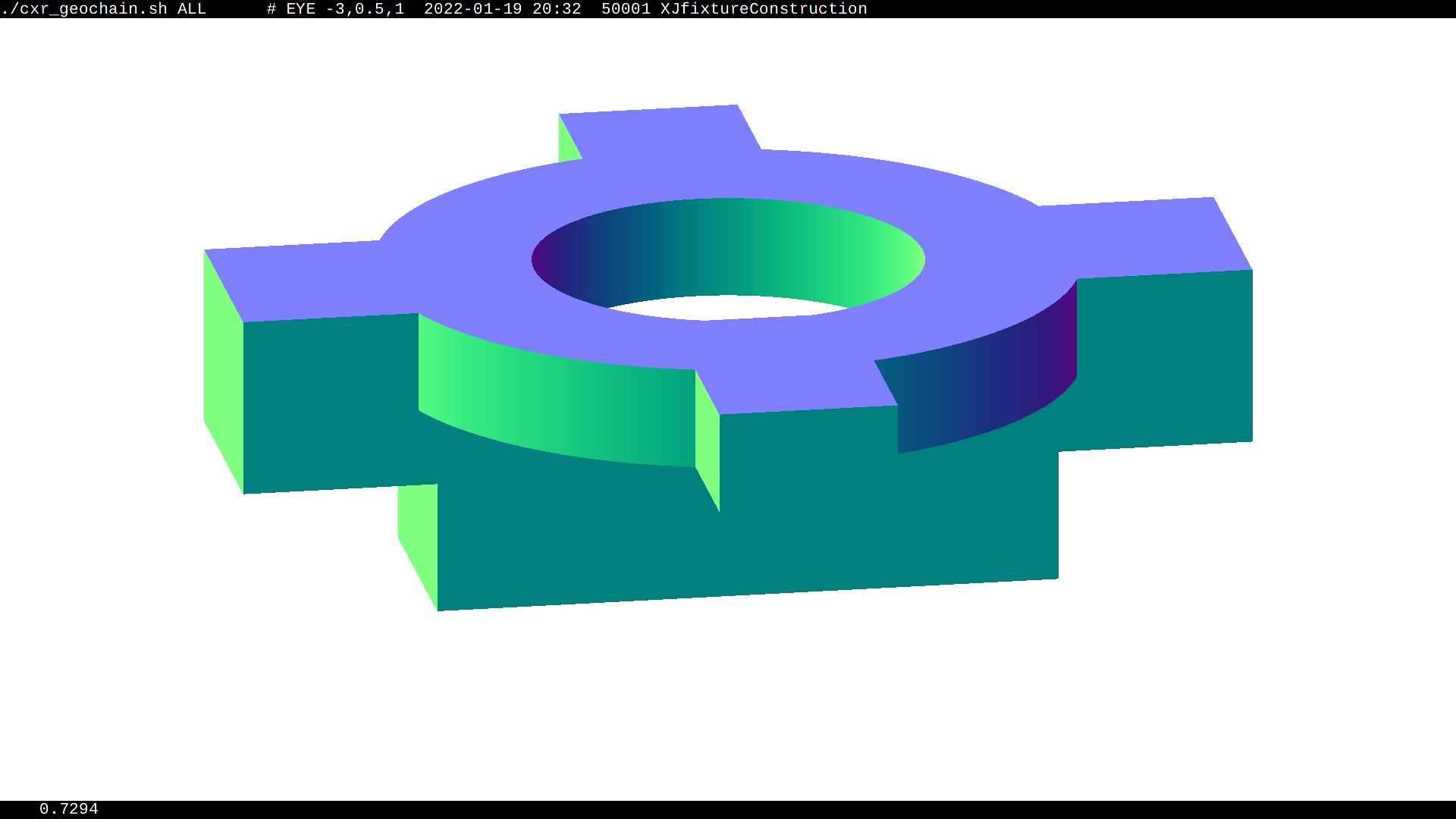
cxr_overview_emm_t0_elv_t_moi__ALL_with-debug-disable-xj.jpg
cxr_min__eye_-10,0,0__zoom_0.5__tmin_0.1__sChimneyAcrylic_increased_TMAX.jpg
Raytrace render view from inside JUNO Water Buffer
cxr_overview_emm_image_grid_overview
- Comparison of ray traced render times of different geometry
- simple way to find issues, eg over complex CSG, overlarge BBox
image_grid_elv_scan.jpg
Spot the differences : from volume exclusions
scan-pf-check-GUI-TO-SC-BT5-SD
scan-pf-check-GUI-TO-BT5-SD
n-ary CSG Compound "List-Nodes" => Much Smaller CSG trees
- Communicate shape more precisely
- => better suited intersect alg => less resources => faster
Generalized Opticks CSG into three levels : tree < node < leaf
Generalizes binary to n-ary CSG trees
- list-node references sub-nodes by subNum subOffset
- CSG_CONTIGUOUS Union
- user guarantees contiguous, like G4MultiUnion of prim
- CSG_DISCONTIGUOUS Union
- user guarantees no overlaps, eg "union of holes" to be CSG subtracted : => simple, low resource intersect
- CSG_OVERLAP Intersection
- user guarantees overlap, eg general G4Sphere: inner radius, thetacut, phicut
Promising approach to avoid slowdowns from complex CSG solids
CSG_DISCONTIGUOUS Union : CSG intersection
User guarantees : absolutely no overlapping between constituents
+-------+ +-------+ +-------+ +-------+ +-------+
| | | | | | | | | |
| | | | | | | | | |
+-------+ +-------+ +-------+ +-------+ +-------+
+-------+ +-------+ +-------+ +-------+ +-------+
| | | | | | | | | |
| | | | | | | | | |
+-------+ +-------+ +-------+ +-------+ +-------+
- => very simple low resource intersection : closest Enter or Exit
- More closely suiting algorithm to geometry => better performance
- this can help with "holes" subtracted from another solid : the "holes" usually do not overlap
QUDARap : CUDA Optical Simulation Implementation
CPU/GPU Counterpart Code Organization for Simulation
| |
CPU |
GPU |
|---|
| context steering |
QSim.hh |
qsim.h |
| curandState setup |
QRng.hh |
qrng.h |
| property interpolation |
QProp.hh |
qprop.h |
| event handling |
QEvent.hh |
qevent.h |
| Cerenkov generation |
QCerenkov.hh |
qcerenkov.h |
| Scintillation generation |
QScint.hh |
qscint.h |
| texture handling |
QTex.hh |
cudaTextureObject_t |
- facilitate fine-grained modular testing
- bulk of GPU code in simple to test headers
- test most "GPU" code on CPU, eg using mock curand
- QUDARap does not depend on OptiX -> more flexible -> simpler testing
Validation of Opticks Simulation(A) by Comparison with Geant4 Sim. (B)
A and B always same photon counts (due to gensteps)
- direct comparison when simulations are random aligned
- when not aligned : statistical Chi2 history comparison
- compare history frequencies, Chi2 points to issues
Primary Issue : double vs float, also:
- geometry bugs : overlaps, coincident faces
- grazing incidence, edge skimmers
After debugged : fraction of percent diffs
Optical Performance : Very dependent on geometry + modelling
After avoiding geometry problems : G4Torus, deep CSG trees
- have achieved > 1500x Geant4 [1]
- removes optical bottlenecks : memory + processing
[1] Single threaded Geant4 10.4.2, NVIDIA Quadro RTX 8000 (48G), 1st gen RTX, ancient JUNO geom, OptiX 6.5, ancient Opticks
Optical Simulation Comparison : Statistical OR Direct
Statistical Chi-squared comparison of photon history occurence between two simulations
- powerful metric to find discrepancies between simulations (eg from near-degenerate geometry)
c2sum/c2n:c2per(C2CUT) 280.88/188:1.494 (30)
np.c_[siq,_quo,siq,sabo2,sc2,sabo1][0:25] ## A-B history frequency chi2 comparison
0 TO BT BT BT BT SD 33322 33343 0.0066 1 2
1 TO BT BT BT BT SA 28160 28070 0.1441 8 0
2 TO BT BT BT BT BT SR SA 6270 6268 0.0003 10363 10565
3 TO BT BT BT BT BT SA 4552 4649 1.0226 8398 8433
4 TO BT BT BT BT BT SR BR SR SA 1154 1186 0.4376 21156 21014
5 TO BT BT BT BT BT SR BR SA 923 989 2.2782 20241 20201
6 TO BT BT BT BT BR BT BT BT BT BT BT AB 946 958 0.0756 10389 8432
7 TO BT BT BT BT BT SR SR SA 901 942 0.9121 10399 10410
8 TO BT BT AB 878 895 0.1630 26 102
9 TO BT BT BT BT BT SR BT BT BT BT BT BT BT AB 615 635 0.3200 20974 22027
10 TO BT BT BT BT BR BT BT BT BT AB 571 601 0.7679 8459 9208
11 TO BT BT BT BT BR BT BT BT BT BT BT BT BT SA 533 537 0.0150 7312 7299
12 TO BT BT BT BT BR BT BT BT BT BT BT BT BT BT BT BT BT SD 503 396 12.7353 12018 11465
13 TO BT BT BT BT BR BT BT BT BT BT BT BT BT SD 480 497 0.2958 7974 7967
14 TO BT BT BT BT BR BT BT BT BT BT BT BT BT BT BT BT BT SA 412 411 0.0012 11467 11471
15 TO BT BT BT BT BT SR SR SR SA 383 396 0.2169 10362 10368
When causes of discrepancy cannot be identified statistically
- use common input photons + aligned random consumption between simulations
- enable direct photon-to-photon comparison of simulations : reveals precisely where simulations diverge
Comparison of two independent optical simulation implementations : ideal way find issues
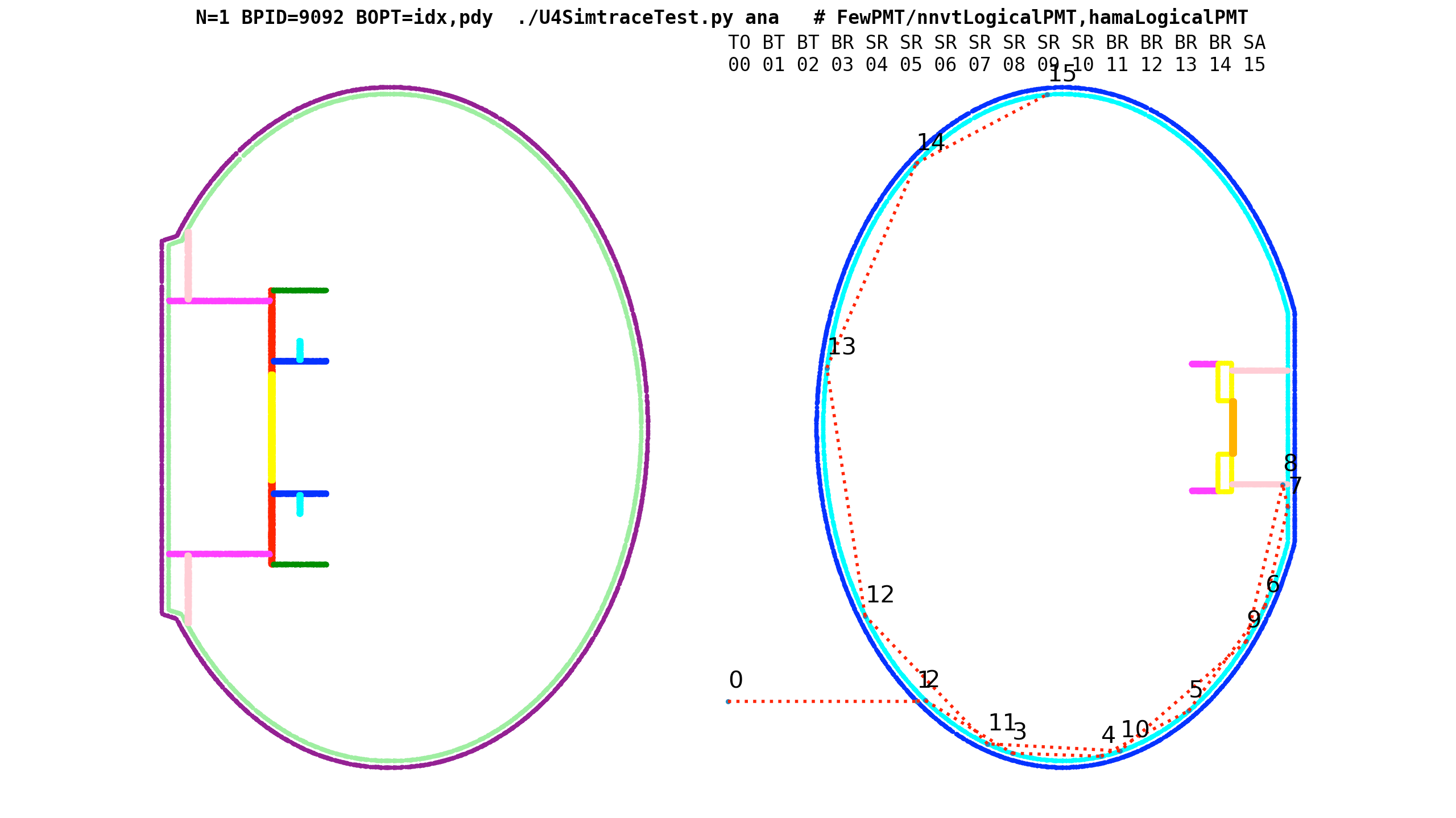
B_V1J008_N1_ip_MOI_Hama:0:1000_yy_frame_close.png
Green : start position (100k input photons)
Red : end position, Cyan : other position
B_V1J008_N1_ip_MOI_Hama:0:1000_b.png
cd ~/j/ntds ; N=1 ./ntds.sh ana
Geant4/U4Recorder 3D photon points transformed into target frame, viewed in 2D
B_V1J008_N1_OIPF_NNVT:0:1000_gridxy.png
export OPTICKS_INPUT_PHOTON=GridXY_X1000_Z1000_40k_f8.npy
export OPTICKS_INPUT_PHOTON_FRAME=NNVT:0:1000
MODE=3 EDL=1 N=0 EYE=500,0,2300 CHECK=not_first ~/j/ntds/ntds.sh ana
Photon step points from grid of input photons target NNVT:0:1000 (POM:1)
cxr_min__eye_1,0,5__zoom_2__tmin_0.5__NNVT:0:1000_demo.jpg
ray traced renders : exact same geometry "seen" by simulation
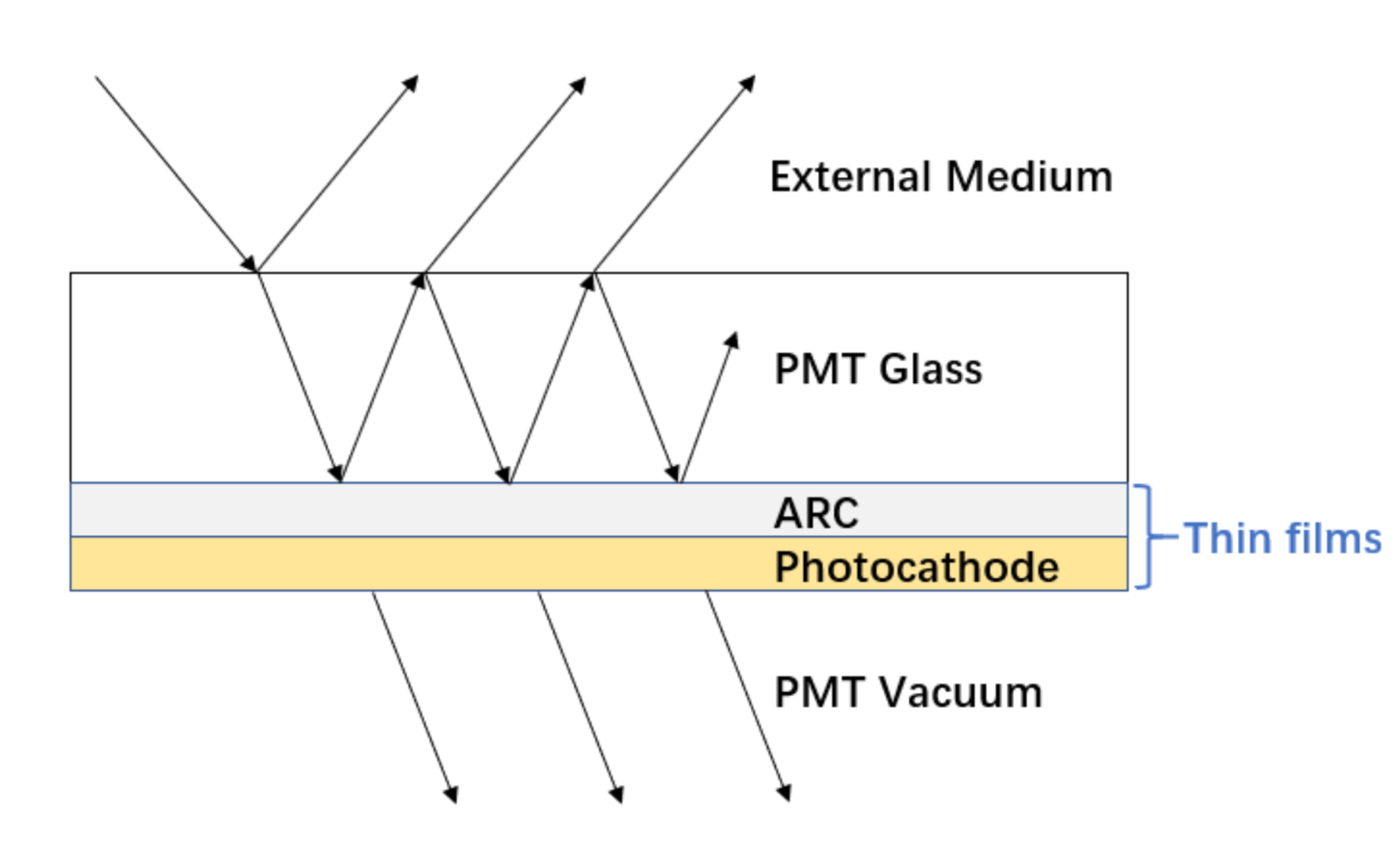
Multi-Layer Thin Film (A,R,T) Calc using TMM Calc (Custom4 Package)
- C4OpBoundaryProcess.hh
- G4OpBoundaryProcess with C4CustomART.h
- C4CustomART.h
- integrate custom boundary process and TMM calculation
- C4MultiLayrStack.h : CPU/GPU TMM calculation of (A,R,T)
based on complex refractive indices and layer thicknesses
- GPU: using thrust::complex CPU:using std::complex
Custom4: Simplifies JUNO PMT Optical Model + Geometry
LayrTest__R12860_Aspa.png
Amdahls "Law" : Expected Speedup Limited by Serial Processing
optical photon simulation, P ~ 99% of CPU time
- -> potential overall speedup S(n) is 100x
- even with parallel speedup factor >> 1000x
Must consider processing "big picture"
- remove bottlenecks one by one
- re-evaluate "big picture" after each
amdahl_p_sensitive.png
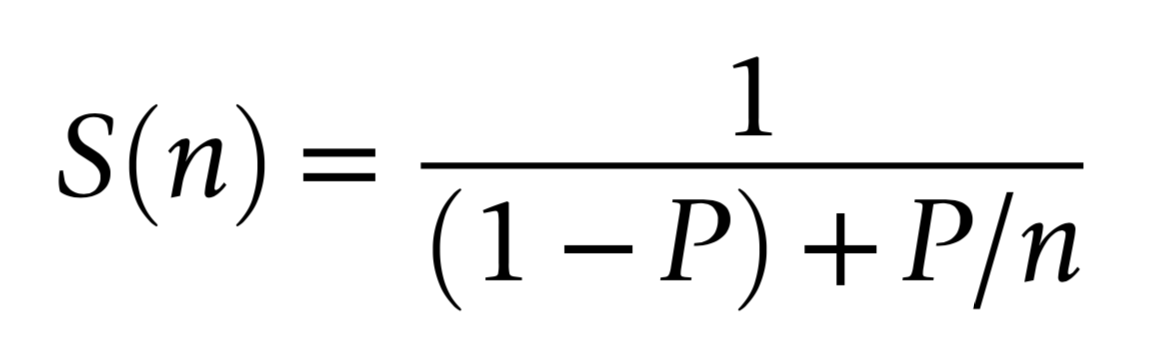
How much parellelized speedup actually useful to overall speedup?
Very dependant on the parallel fraction
| Theoretical Overall Speedup for various parallel fractions and parallelized speedups |
|---|
| |
Parallelized Speedup |
|
|---|
| Parallel Fraction |
100x |
1000x |
limit |
Notes |
|---|
| 95% |
17x |
20x |
20x |
Little benefit beyond ~100x parallelized speedup |
| 96% |
20x |
24x |
25x |
| 97% |
25x |
32x |
33.3x |
| 98% |
34x |
48x |
50x |
Substantial benefit from more parallelized speedup |
| 99% |
50x |
91x |
100x |
In [1]: run ~/opticks/ana/amdahl.py
In [2]: Amdahl.Overall_Speedup(np.array([100,1000,np.inf]),0.95)
Out[2]: array([16.807, 19.627, 20. ])
In [3]: Amdahl.Overall_Speedup(np.array([100,1000,np.inf]),0.99)
Out[3]: array([ 50.251, 90.992, 100. ])
Summary and Links
Opticks : state-of-the-art GPU ray traced optical simulation integrated with Geant4.
Full re-implementation of Opticks geometry and simulation for NVIDIA OptiX 7 completed.
- NVIDIA Ray Trace Performance continues rapid progress (2x each generation)
- any simulation limited by optical photons can benefit from Opticks
- more photon limited -> more overall speedup (99% -> 100x)