JUNOSW + Opticks : Status and Plan
JUNOSW + Opticks : Status and Plan
- (December 18, 2023) First Pre-Release of JUNOSW+Opticks
- Status of known issues : most leaks now fixed
- Opticks additions to assist with GPU+CPU memory leak finding
- Geometry in use based on J23_1_0_rc3
- Introduce Three Opticks test scripts [1] [2] [3]
- [2] A:B Chi2 comparison of optical propagation history frequencies
- [2] Chimney Issue : Photons going up the Chimney discrepant ?
- [3] Pure Optical TorchGenstep 20 evt scan : 0.1M to 100M photons
- [3] Hit vs Photon for Release build running
- Optimizing separate "Release" build in addition to "Debug" build
- [3] Event Time vs Photon in Debug and Release builds
- Absolute Comparison with ancient Opticks Measurements ?
- Launch time (and hits) vs OPTICKS_MAX_BOUNCE
- Yuxiang Hu : Gamma Event at CD center comparisons
- Amdahls Law : How much parellelized speedup actually useful to overall speedup ?
- NEXT STEPS/PLAN
- Opticks Links, JUNOSW+Opticks DocDB
Simon C Blyth, IHEP, CAS — Offline Software Review — 24 Feb 2024
(December 18, 2023) First Pre-Release of JUNOSW+Opticks
source /cvmfs/juno.ihep.ac.cn/centos7_amd64_gcc1120_opticks/Pre-Release/J23.1.0-rc6/setup.sh
- Objective of Pre-Release : enable non-developers to test JUNOSW+Opticks
| OptiX 7.5 | Chosen to match NVIDIA CUDA 11.7 + Driver Version: 515.65.01 on IHEP GPU cluster |
| Geant4 10.4.2 | (Opticks with Geant4 11 already in use by Fermilab Geant4 group, others) |
| Custom4 0.1.8 | small package : but deeply coupled with : Geant4 + JUNOSW + Opticks |
| Opticks-v0.2.4 | December 18 release https://github.com/simoncblyth/opticks/releases/tag/v0.2.4 |
Pre-Release usable only on IHEP GPU cluster (?)
- unless NVIDIA Driver + CUDA + OptiX versions happen to match your machine
Example test scripts in j repository:
- https://code.ihep.ac.cn/blyth/j/-/blob/main/okjob.sh slurm submission wrapper
- https://code.ihep.ac.cn/blyth/j/-/blob/main/jok.bash tut_detsim.py commandline
Example job script for developers building JUNOSW+Opticks with bash junoenv opticks,bash junoenv offline
Status of known issues : most leaks now fixed
- sensor_identifier off-by-one bug (caused SEGV on hitting SPMT 325599)
- FIX: 2023/12/19 Opticks v0.2.5
- GPU memory leak : from creating CUDA stream for every launch
- FIX: 2024/01/25 Opticks v0.2.6 (GPU leak : difficult to find, easy to fix)
- CPU memory leak from hit handling (CPU leak : re-implement more cleanly)
- FIX: 2024/02/20 Opticks HEAD via reimplementation of SEvt::getLocalHit
- leak investigated with standalone test : u4/tests/U4HitTest.sh
- fix avoids transform related leak
- fix avoids transform inversion for each hit, adopts double precision transforms
- FIX: 2024/02/20 Opticks HEAD via reimplementation of SEvt::getLocalHit
- U4Recorder CPU memory leak, non-critical
- recorder only used for debug + validation
- no need to handle many or large (100M photon) events
- TODO : check again, above hit handling fix might reduce this enough already
- python analysis/plotting machinery not yet included in release
- geometry differences described separately
Opticks additions to assist with GPU+CPU memory leak finding
- ~/opticks/sysrap/smonitor.sh
- NVML based GPU memory monitor (~nvidia-smi with NumPy array saving)
- ~/opticks/sysrap/tests/sprof.sh
- Analysis of sysrap/SProf.hh (time[us],VM[kb],RSS[kb]) CPU memory profile stamps
- 2024/01/22 : complete impl. of running from sequence of input gensteps
- rerun GPU optical propagation with gensteps persisted from JUNOSW+Opticks job
- ADVANTAGE : optical simulation dev. cycle time < 2 seconds (not 2 minutes)
- enabled pinning down VRAM launch leak : without waiting 2 minutes between trials
- see ~/opticks/CSGOptiX/cxs_min_igs.sh
export OPTICKS_INPUT_GENSTEP=$BASE/jok-tds/ALL0/A%0.3d/genstep.npy ## sequence of genstep arrays to load across multiple SEvt folders
- 2024/02/04 : complete sysrap/NPX.h additions for std::unordered_map
- JUNOSW map -> unordered_map required additional NPX.h serialize/import methods
cxr_min__eye_0,1.5,0__zoom_4__tmin_1.3__ALL.jpg
EYE=0,1.5,0 TMIN=1.3 ZOOM=4 ~/opticks/cxr_min.sh ## CSGOptiXRMTest
Using GEOM J23_1_0_rc3_ok0
Geometry in use based on J23_1_0_rc3
Deferred geometry, switched off by tut_detsim.py options.
| --no-guide_tube | OptiX 7.1 has curves : thought might enable G4Torus translation, but docs show are one-sided : so instead triangulate torus[T] ? | |
| --debug-disable-xj | XJfixture XJanchor | Deep CSG trees require dev. to see if "listnode" (similar to G4MultiUnion) can provide solution |
| --debug-disable-sj | SJCLSanchor SJFixture SJReceiver SJFixture | |
| --debug-disable-fa | FastenerAcrylic | |
Virtual surface shifts used to avoid degeneracy, together with defaults (shifts avoid chi2 discrepancies from degenerate surfaces):
export Tub3inchPMTV3Manager__VIRTUAL_DELTA_MM=0.10 ## 1.e-3 export HamamatsuMaskManager__MAGIC_virtual_thickness_MM=0.10 ## 0.05 export NNVTMaskManager__MAGIC_virtual_thickness_MM=0.10 ## 0.05
- TODO: check virtual shifts have no performance effects or overlap issues
- convince offline group to enlarge defaults : avoiding these Opticks only shifts
- TODO: add optional triangulated geometry handling : use for guide tube
- torus quartic analytic solution painful : expect triangulation approximation more robust+precise
- TODO: test "listnode" solution for handling deep CSG trees (complex solid shape)
Completing these three : will match GPU and CPU geometry
Introduce Three Opticks test scripts [1] [2] [3]
| idx | control script | initialization time (seconds) | Notes |
|---|---|---|---|
| [1] | ~/j/okjob.sh | 149 | JUNOSW+Opticks (tut_detsim.py "main") |
| [2] | ~/opticks/g4cx/tests/G4CXTest_GEOM.sh | 127 | InputPhoton, TorchGenstep, NOT YET InputGenstep |
| [3] | ~/opticks/CSGOptiX/cxs_min.sh | <2 | InputPhoton, TorchGenstep, InputGenstep |
- "insitu" test of Opticks embedded into JUNOSW : translates geometry and persists it
- standalone optical only bi-simulation for A:Opticks <=> B:Geant4 comparison
- pure Opticks (no Geant4 dependency) GPU optical simulation : uses geometry persisted by [1]
- fast initialization : loads CSGFoundry geometry and uploads to GPU in <2 seconds
- fast cycle for development and Opticks performance measurements
- TorchGenstep
- disc, sphere, line, point, circle, rectangle : shapes of photon sources implemented in sysrap/storch.h
- InputGenstep
- general gensteps eg obtained from [1]:okjob.sh can be used in [3]:cxs_min.sh, not yet [2]:G4CXTest (expect straightforward)
[2] A:B Chi2 comparison of optical propagation history frequencies
~/o/G4CXTest_GEOM.sh ana ## python history comparison ~/o/sysrap/tests/sseq_index_test.sh ## C++ history comparison
a_path $AFOLD/seq.npy /data/blyth/opticks/GEOM/J23_1_0_rc3_ok0/G4CXTest/ALL98/A000/seq.npy a_seq (1000000, 2, 2, )
b_path $BFOLD/seq.npy /data/blyth/opticks/GEOM/J23_1_0_rc3_ok0/G4CXTest/ALL98/B000/seq.npy b_seq (1000000, 2, 2, )
AB [sseq_index_ab::desc u.size 152520 opt BRIEF mode 6
sseq_index_ab_chi2::desc sum 565.3332 ndf 504.0000 sum/ndf 1.1217 sseq_index_ab_chi2_ABSUM_MIN:200.0000
TO AB : 126549 126745 : 0.1517 : Y : 2 7 :
TO BT BT BT BT BT BT SD : 70494 70397 : 0.0668 : Y : 18 2 :
TO BT BT BT BT BT BT SA : 57103 57388 : 0.7094 : Y : 5 1 :
TO SC AB : 51434 51094 : 1.1275 : Y : 4 48 :
TO SC BT BT BT BT BT BT SD : 35878 35913 : 0.0171 : Y : 58 56 :
TO SC BT BT BT BT BT BT SA : 29676 30061 : 2.4813 : Y : 124 85 :
TO SC SC AB : 19993 19869 : 0.3857 : Y : 137 24 :
TO BT BT SA : 18932 18869 : 0.1050 : Y : 71 148 :
TO RE AB : 18319 18090 : 1.4403 : Y : 9 50 :
TO SC SC BT BT BT BT BT BT SD : 15454 15326 : 0.5323 : Y : 19 8 :
TO SC SC BT BT BT BT BT BT SA : 12785 12833 : 0.0899 : Y : 24 138 :
TO BT BT AB : 10993 10949 : 0.0882 : Y : 72 26 :
TO BT AB : 9250 9279 : 0.0454 : Y : 36 13 :
TO BT BT BT BT BT BT BT SA : 7476 7577 : 0.6777 : Y : 176 634 :
TO SC SC SC AB : 7544 7418 : 1.0611 : Y : 90 82 :
TO RE BT BT BT BT BT BT SD : 7419 7272 : 1.4709 : Y : 197 73 :
TO SC RE AB : 7137 7049 : 0.5459 : Y : 110 11 :
...
| Test | Status |
|---|---|
| InputPhotons targetting PMTs | chi2 matched, no known issues |
| TorchGenstep from CD center | chi2 marginal : chimney issue ? Probably some coincident surfaces to fix |
[2] Chimney Issue : Photons going up the Chimney discrepant ?
np.c_[siq,_quo,siq,sabo2,sc2,sabo1][bzero] ## history seq in A but not B : usually from degeneracy [['1107' 'TO BT BT BT BT BT BT BT BT SD ' '1107' ' 41 0' ' 0.0000' ' 11355 -1'] ['1305' 'TO BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT' '1305' ' 33 0' ' 0.0000' ' 11040 -1'] ['1623' 'TO BT BT DR BT BT BT SD ' '1623' ' 26 0' ' 0.0000' ' 1930 -1'] ['2375' 'TO BT BT BT BT BT BT BR BT BT BT BT BT BT BT BT BT SD ' '2375' ' 17 0' ' 0.0000' ' 10972 -1'] ['3264' 'TO SC BT BT BT BT BT BT BR BT BT BT BT BT BT BT BT BT SD ' '3264' ' 12 0' ' 0.0000' ' 22140 -1']] In [1]: w = a.q_startswith("TO BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT BT") ; w Out[1]: array([ 11040, 15219, 118322, 152607, 165838, 215978, 299136, 374379, 395244, 422394, 427598, 434101, 443666, 445392, 479186, 531698, 549984, 592656, 604821, 637582, 656052, 736283, 777988, 789501, 821402, 837105, 853410, 898084, 903045, 923645, 927731, 974750, 989689]) In [2]: a.f.record[w[0],:,0] ## PHOTON STEP POINT POSITIONS : ALL SIMILAR : GOING UP THE CHIMNEY Out[2]: array([[ -1.594, 0.835, 99.984, 0. ], ## photon step point (x,y,z,t) mm,ns [ -284.142, 148.854, 17823.998, 81.302], [ -315.513, 165.289, 20000. , 88.563], [ -332.369, 174.119, 21750. , 94.401], [ -332.383, 174.127, 21752. , 94.407], [ -344.817, 180.641, 23500. , 103.396], [ -368.795, 193.202, 25752. , 110.911], [ -409.762, 214.663, 29599.7 , 123.75 ], [ -409.764, 214.664, 29599.85 , 123.75 ], ... [ -412.414, 216.053, 29848.799, 124.581], [ -412.424, 216.058, 29849.7 , 124.584], [ -412.426, 216.059, 29849.85 , 124.585], [ -412.532, 216.114, 29859.85 , 124.618], [ -412.534, 216.115, 29860. , 124.618], [ -412.543, 216.12 , 29860.9 , 124.621], [ -412.55 , 216.124, 29861.5 , 124.623], [ -412.56 , 216.129, 29862.5 , 124.627]], dtype=float32)
Investigating a discrepant Chimney photon : more of this + geometry examination needed to find cause of difference
[3] Pure Optical TorchGenstep 20 evt scan : 0.1M to 100M photons
TEST=large_scan ~/opticks/cxs_min.sh
Generate 20 optical only events with 0.1M->100M photons starting from CD center, gather and save only Hits.
- uses CSGOptiXSMTest executable (no Geant4 dependency)
OPTICKS_RUNNING_MODE=SRM_TORCH ## "Torch" running enables num_photon scan OPTICKS_NUM_PHOTON=H1:10,M2,3,5,7,10,20,40,60,80,100 OPTICKS_NUM_EVENT=20 OPTICKS_EVENT_MODE=Hit
- no Geant4 initialization (~150s) : load and upload geometry in ~2s
- BUT with MAX_PHOTON 100M, uploading curandState costs 20s
| Test Hardware | Notes |
|---|---|
| DELL Precison Workstation with NVIDIA TITAN RTX(24G) | Primary test hardware |
| DELL Precision Workstation with NVIDIA TITAN V(12G) | VRAM limited |
| DELL Precision Workstation with NVIDIA Quadro RTX 8000 (48G) | TODO : push to memory limit ~400M photons |
| GPU cluster nodes with NVIDIA V100 (32GB) | TODO: Production Config Testing, expect ~250M photon per launch limit |
ALL1_scatter_10M_photon_22pc_hit_alt.png
~/o/cxs_min.sh ## 2.2M hits from 10M photon TorchGenstep, 3.1 seconds
ALL1_scatter_10M_photon_22pc_hit.png
S7_Substamp_ALL_Hit_vs_Photon__linear.png
Optimizing separate "Release" build in addition to "Debug" build
Release preprocessor macros : adds: PRODUCTION , removes: DEBUG_TAG, DEBUG_PIDX,...
- remove debug array collection (eg photon step point records)
- remove debug code from GPU kernels
- lots more mileage here : more can be removed from Release kernel
Examine flattened kernel source CSGOptiX/CSGOptiX7.cu (103k lines) : all includes included
~/opticks/preprocessor.sh > /tmp/out.cc ## using gcc -E -C -P
- see what the compiler sees
- enables finding inadvertent doubles + printf
Grepping Kernel PTX : Parallel Thread Execution ~Assembly code
- examine first stage output from compilation
Grepping PTX for doubles and printf, and then removing from source : opticks-ptx bash function eg:
grep \\.f64 $OPTICKS_PREFIX/ptx/CSGOptiX_generated_CSGOptiX7.cu.ptx
- with OptiX 6.5 removing doubles had large performance improvements, no big effects yet with 7.5
N7_Substamp_ALL_Etime_vs_Photon__34s_100M_debug.png
Debug : 0.341 seconds per million photons
S7_Substamp_ALL_Etime_vs_Photon__100M_31s_Release.png
Release : 0.314 seconds per million photons
scan-pf-1_Opticks_vs_Geant4 2
Absolute Comparison with ancient Opticks Measurements.. ? [Below presented at CHEP 2019] 58s / 400M photons
| JUNO analytic, 400M photons from center | Speedup | |
|---|---|---|
| Geant4 Extrap. | 95,600 s (26 hrs) | |
| Opticks RTX ON (i) | 58 s | 1650x |
Absolute Comparison with ancient Opticks Measurements ?
| JUNO analytic, 400M photons from center | Speedup | Notes | |
|---|---|---|---|
| Geant4 Extrap. | 95,600 s (26 hrs) | Ancient (2019) | |
| Opticks RTX ON (i) | 58 s | 1650x | Ancient (2019) |
| JUNOSW+Opticks 1st | 124 s (~2x slower) | "770x" | extrapolated from 31s for 100M |
Practically everything different between these measurements : nevertheless, its natural to compare
- NVIDIA OptiX 6.5 -> 7.5 [entirely new API] => Opticks almost entirely re-implemented
- JUNO geometry : more complex than 4 years ago(?) : despite efforts to simplify
- JUNO PMT Optical Model (POM) (traditional vs "bouncy" with complex {A,R,T} TMM calculation)
- NVIDIA RTX 8000 (48G) vs NVIDIA TITAN RTX (24G) [similar spec other than VRAM]
- Geant4 setup : Geant4 is not a good candle : far too flexible
~300 ns photon lifetime limit ?
- long path photons : relevant ? how expensive ?
- TODO : try chop tail
OPTICKS_MAX_BOUNCE=32 ## curr. OPTICKS_MAX_NS=300 ## IDEA
Expected Primary Cause of 2x slowdown : "bouncy" POM
- many more photons living longer, not "mopped" up by PMTs
- bouncing around inside PMT, visiting multiple PMTs
- more bounces -> every bounce costing a ray trace
- more divergence -> less parallelism
N6_Substamp_ONE_maxb_scan_A_expensive_tail.png
Use cxs_min_scan.sh to vary OPTICKS_MAX_BOUNCE from 0->32
- linear time increase up to max bounce ~18
- every ray trace is costing about same
- warp stagglers holding down performance ?
N6_Substamp_ONE_maxb_scan_HIT__slow_hit_increase.png
Slow hit increase above MAX_BOUNCE 20
hit_position_wavelength_time.png
Yuxiang Hu : Gamma Event at CD center : Comparison of JUNOSW with JUNOSW+Opticks
Hit position, wavelength and time comparison
- TODO: propagation comparison to understand ~2% hit difference
gamma_event_at_center.png
Yuxiang Hu : Gamma Event at CD center : Comparison of JUNOSW with JUNOSW+Opticks
| Overall speedup [JSW/(JSW+Opticks)] | ~60X | UN-OPTIMIZED + PRELIM |
[Calculation: same TMM header as JUNOSW, Lookup: using uploaded "ART" texture (Gigabytes)]
- TODO: higher energies, muon, multi-muon, ...
Amdahls "Law" : Expected Speedup Limited by Serial Processing
S(n) Expected Speedup
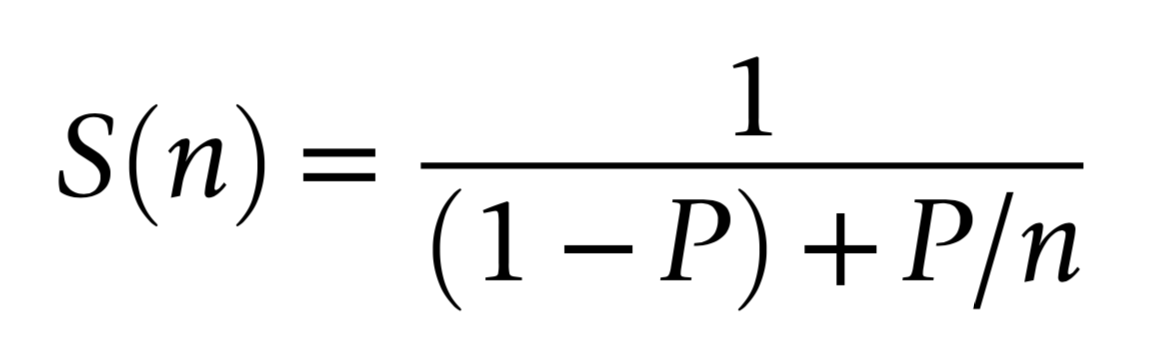
- P
- parallelizable proportion
- 1-P
- non-parallelizable portion
- n
- parallel speedup factor
optical photon simulation, P ~ 99% of CPU time
- -> potential overall speedup S(n) is 100x
- even with parallel speedup factor >> 1000x
Must consider processing "big picture"
- remove bottlenecks one by one
- re-evaluate "big picture" after each
amdahl_p_sensitive.png
How much parellelized speedup actually useful to overall speedup?
Very dependant on the parallel fraction
| Theoretical Overall Speedup for various parallel fractions and parallelized speedups | ||||
|---|---|---|---|---|
| Parallelized Speedup | ||||
| Parallel Fraction | 100x | 1000x | limit | Notes |
| 95% | 17x | 20x | 20x | Little benefit beyond ~100x parallelized speedup |
| 96% | 20x | 24x | 25x | |
| 97% | 25x | 32x | 33.3x | |
| 98% | 34x | 48x | 50x | Substantial benefit from more parallelized speedup |
| 99% | 50x | 91x | 100x | |
In [1]: run ~/opticks/ana/amdahl.py In [2]: Amdahl.Overall_Speedup(np.array([100,1000,np.inf]),0.95) Out[2]: array([16.807, 19.627, 20. ]) In [3]: Amdahl.Overall_Speedup(np.array([100,1000,np.inf]),0.99) Out[3]: array([ 50.251, 90.992, 100. ])
NEXT STEPS / PLAN
- Release
- create 2nd JUNOSW+Opticks release (with Tao) : after some(but not all) of the below completed
- Fix Leaks
- GPU VRAM leak
- CPU hit handling leak
- U4Recorder CPU memory leak (less important than other leaks : as only used for validation/debug)
- Geometry+Validation
- investigate small photon history chi2 deviations : Chimney geometry degeneracy ?
- check PMT virtual Water/Water wrapper shifts for overlaps/performance effect ?
- add optional triangulated geometry handling : use for guide tube (reviving functionality from old Opticks)
- test listnode solution for complex CSG solids (new "territory", tree balancing not viable)
- Optimization
- further slimming "Release" kernel : only do what must be done, header minimize
- add OPTICKS_MAX_TIME limit, measure performance using eg 200-400ns : understand performance drivers
- compare traditional vs bouncy POM : is bouncy POM primary culprit for 2x slowdown vs ancient measurements ?
- try NVIDIA Nsight kernel profiling tools : look for low hanging fruit
- try OptiX PTX=>IR (Intermediate Representation) [from OptiX 7.1] : "GPU debug, ...enhanced optimizations..."
- Production Preparation
- gain muon running experience : is OPTICKS_MAX_PHOTON hard limit problematic in practice ?
- automated event splitting, depending on num photons and available/configured max VRAM (like Fermilab G4 group)
- config tuning to maximize GPU cluster throughput (expect near-filling VRAM best for 1 node, for cluster too ?)
- LESS IMMINENTLY: automated/configurable event joining ? can this extend usefulness to lower energy events ?
Opticks Links, JUNOSW+Opticks DocDB
| https://bitbucket.org/simoncblyth/opticks | code repository (day-to-day) |
| https://github.com/simoncblyth/opticks | code repository (~month-to-month), releases |
| https://simoncblyth.bitbucket.io https://simoncblyth.github.io https://juno.ihep.ac.cn/~blyth/ | publications, presentations, videos |
| https://groups.io/g/opticks | forum/mailing list archive |
| email:opticks+subscribe@groups.io | subscribe to mailing list |
JUNOSW+Opticks
| DocDB-10968 | 2023/12/19 | Using first JUNOSW+Opticks Pre-Release at IHEP GPU cluster |
| DocDB-10929 | 2023/12/11 | JUNOSW + Opticks : Profiling and Status |