Opticks : GPU Optical Photon Simulation via NVIDIA OptiX 7 and NVIDIA CUDA
Opticks : GPU Optical Photon Simulation via NVIDIA® OptiX™ 7, NVIDIA® CUDA™
Open source, https://bitbucket.org/simoncblyth/opticks

Simon C Blyth, IHEP, CAS — Workshop on HEP Computing and Software — SDU, Qingdao, 11 June 2023
Outline

- Optical Photon Simulation : Context and Problem
- Jiangmen Underground Neutrino Observatory (JUNO)
- JUNO Optical Photon Simulation Problem...
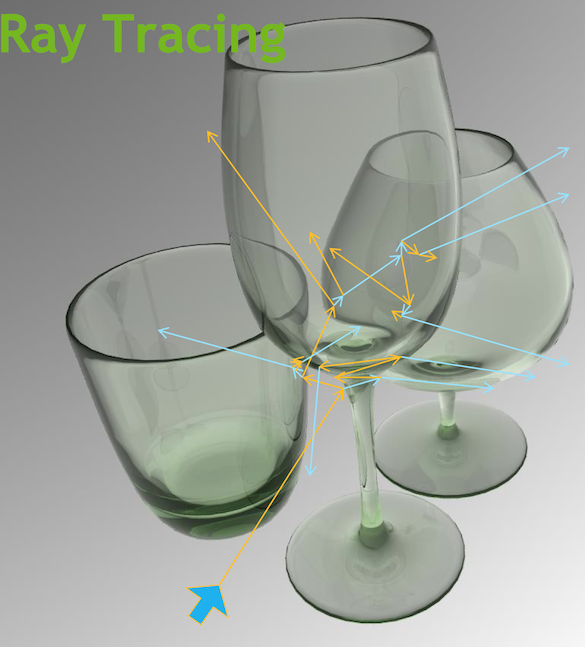
- Optical Photon Simulation ≈ Ray Traced Image Rendering
- NVIDIA Tools to create Solution
- NVIDIA Ada Lovelave : 3rd Generation RTX, RT Cores in Data-Center
- NVIDIA OptiX Ray Tracing Engine
- NVIDIA OptiX 7 : Entirely new thin API, BVH Acceleration Structure
- Opticks : Introduction + Full Re-implementation
- Geant4 + Opticks Hybrid Workflow : External Optical Photon Simulation
- Full re-implementation for NVIDIA OptiX 7 API
- CSGFoundry Geometry Model, Translation to GPU
- Ray trace render performance scanning
- n-Ary CSG "List-Nodes"
- QUDARap : CUDA Optical Simulation Implementation
- Validation
- Opticks : New Features
- Multi-Layer Thin Film (A,R,T) Calc using TMM (Custom4 Package)
- Summary + Links
JUNO_Intro_2
Optical Photon Simulation Problem...
Optical Photon Simulation ≈ Ray Traced Image Rendering
- simulation
- photon parameters at sensors (PMTs)
- rendering
- pixel values at image plane
Much in common : geometry, light sources, optical physics
- both limited by ray geometry intersection, aka ray tracing
Many Applications of ray tracing :
- advertising, design, architecture, films, games,...
- -> huge efforts to improve hw+sw over 30 yrs
NVIDIA Ada : 3rd Generation RTX
- RT Core : ray trace dedicated GPU hardware
- NVIDIA GeForce RTX 4090 (2022)
- 16,384 CUDA Cores, 24GB VRAM, USD 1599
- Continued large ray tracing improvements:
- Ada ~2x ray trace over Ampere (2020), 4x with DLSS 3
- Ampere ~2x ray trace over Turing (2018)
- DLSS : Deep Learning Super Sampling
- AI upsampling, not applicable to optical simulation
Hardware accelerated Ray tracing (RT Cores) in the Data Center
NVIDIA L4 Tensor Core GPU (Released 2023/03)
- Ada Lovelace GPU architecture
- universal accelerator for graphics and AI workloads
- small form-factor, easy to integrate, power efficient
- PCIe Gen4 x16 slot without extra power
- Google Cloud adopted for G2 VMs, successor to NVIDIA T4
- NVIDIA L4 likely to become a very popular GPU
NVIDIA L4 Tensor Core GPU (Data Center, low profile+power)
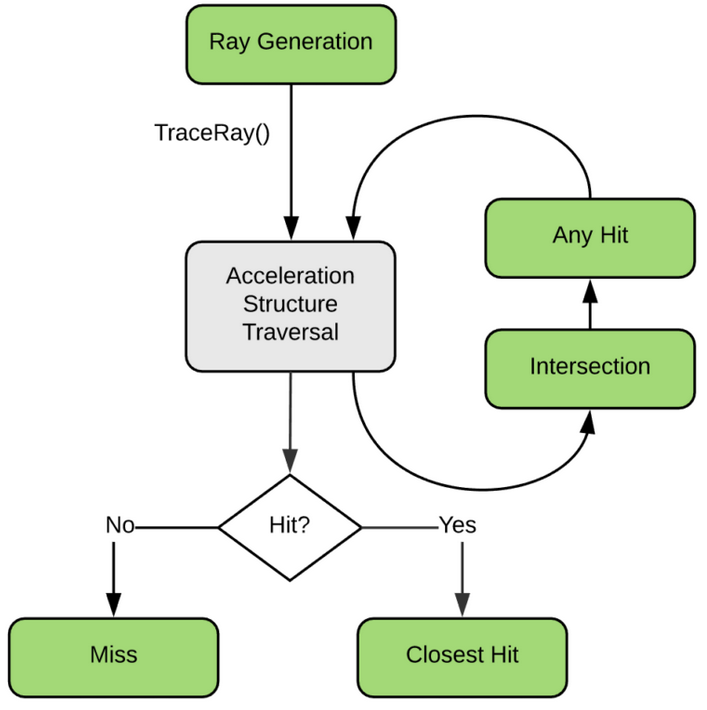
NVIDIA® OptiX™ Ray Tracing Engine -- Accessible GPU Ray Tracing
OptiX makes GPU ray tracing accessible
- Programmable GPU-accelerated Ray-Tracing Pipeline
- Single-ray shader programming model using CUDA
- ray tracing acceleration using RT Cores (RTX GPUs)
- "...free to use within any application..."
OptiX features
- acceleration structure creation + traversal (eg BVH)
- instanced sharing of geometry + acceleration structures
- compiler optimized for GPU ray tracing
https://developer.nvidia.com/rtx/ray-tracing/optix
User provides (Green):
- ray generation
- geometry bounding boxes
- intersect functions
- instance transforms
NVIDIA OptiX 7 : Entirely new thin API => Full Opticks Re-implementation
NVIDIA OptiX 6->7 : drastically slimmed down
- low-level CUDA-centric thin API (Vulkan-ized)
- headers only (no library, impl in Driver)
- Minimal host state, All host functions are thread-safe
- GPU launches : explicit, asynchronous (CUDA streams)
- near perfect scaling to 4 GPUs, for free
- Shared CPU/GPU geometry context
- GPU memory management
- Multi-GPU support
Advantages of 6->7 transition
- More control/flexibility over everything
- Keep pace with state-of-the-art GPU ray tracing
- Fully benefit from current + future GPUs : RT cores, RTX
BUT: demanded full re-implementation of Opticks
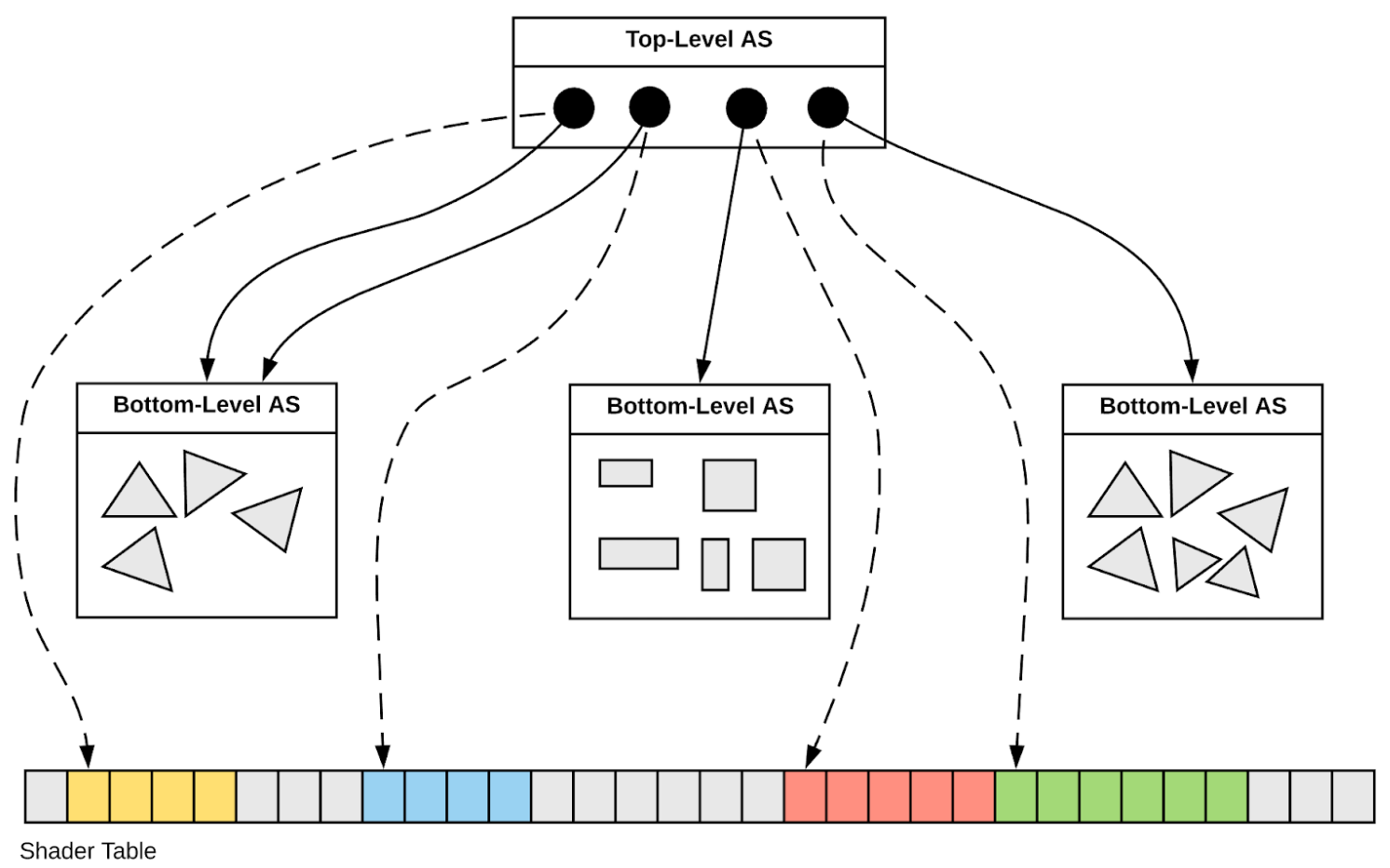
Spatial Index Acceleration Structure
Geant4 + Opticks + NVIDIA OptiX 7 : Hybrid Workflow
| https://bitbucket.org/simoncblyth/opticks |
Opticks API : split according to dependency -- Optical photons are GPU "resident", only hits need to be copied to CPU memory
Geant4 + Opticks + NVIDIA OptiX 7 : Hybrid Workflow 2
Primary Packages and Structs Of Re-Implemented Opticks
- SysRap : many small CPU/GPU headers
- stree.h,snode.h : geometry base types
- sctx.h sphoton.h : event base types
- NP.hh : serialization into NumPy .npy format files
- QUDARap
- QSim : optical photon simulation steering
- QScint,QCerenkov,QProp,... : modular CUDA implementation
- U4
- U4Tree : convert geometry into stree.h
- U4 : collect gensteps, return hits
- CSG
- CSGFoundry/CSGSolid/CSGPrim/CSGNode geometry model
- csg_intersect_tree.h csg_intersect_node.h csg_intersect_leaf.h : CPU/GPU intersection functions
- CSGOptiX
- CSGOptiX.h : manage geometry convert from CSG to OptiX 7 IAS GAS, pipeline creation
- CSGOptiX7.cu : compiled into ptx that becomes OptiX 7 pipeline
- includes QUDARap headers for simulation
- includes csg_intersect_tree.h,.. headers for CSG intersection
- G4CX
- G4CXOpticks : Top level Geant4 geometry interface
Full re-implementation of Opticks for NVIDIA OptiX 7 API
- Huge change unavoidable from new OptiX API --> So profit from rethink of simulation code --> 2nd impl advantage
| Old simulation (OptiXRap) |
New simulation (QUDARap/qsim.h + CSGOptiX, CSG) |
|---|
- implemented on top of old OptiX API
|
- pure CUDA implementation
- OptiX use kept separate, just for intersection
|
- monolithic .cu
- GPU only implementation
- deep stack of support code
|
- many small headers
- many GPU+CPU headers
- shallow stack : QUDARap depends only on SysRap
|
- most code in GPU only context,
even when not needing OptiX or CUDA
|
- strict code segregation
- code not needing GPU in SysRap not QUDARap
|
- testing : GPU only, coarse
|
- testing : CPU+GPU , fine-grained
- curand mocking on CPU
|
- limited CPU/GPU code sharing
|
- maximal sharing : SEvt.hh, sphoton.h, ...
|
- timeconsuming manual random alignment
conducted via debugger
|
- new systematic approach to random alignment
|
Goals of re-implementation : flexible, modular GPU simulation, easily testable, less code
- code reduction, sharing as much as possible between CPU and GPU
- fine grained testing on both CPU and GPU, with GPU curand mocking
- profit from several years of CUDA experience, eg QSim.hh/qsim.h host/device counterpart pattern:
- hostside initializes and uploads device side counterpart --> device side hits ground running
Geometry Model Translation : Geant4 => CSGFoundry => NVIDIA OptiX 7
Geant4 Geometry Model (JUNO: 300k PV, deep hierarchy)
| PV |
G4VPhysicalVolume |
placed, refs LV |
| LV |
G4LogicalVolume |
unplaced, refs SO |
| SO |
G4VSolid,G4BooleanSolid |
binary tree of SO "nodes" |
Opticks CSGFoundry Geometry Model (index references)
| struct |
Notes |
Geant4 Equivalent |
|---|
| CSGFoundry |
vectors of the below, easily serialized + uploaded + used on GPU |
None |
| qat4 |
4x4 transform refs CSGSolid using "spare" 4th column (becomes IAS) |
Transforms ref from PV |
| CSGSolid |
refs sequence of CSGPrim |
Grouped Vols + Remainder |
| CSGPrim |
bbox, refs sequence of CSGNode, root of CSG Tree of nodes |
root G4VSolid |
| CSGNode |
CSG node parameters (JUNO: ~23k CSGNode) |
node G4VSolid |
NVIDIA OptiX 7 Geometry Acceleration Structures (JUNO: 1 IAS + 10 GAS, 2-level hierarchy)
| IAS |
Instance Acceleration Structures |
JUNO: 1 IAS created from vector of ~50k qat4 (JUNO) |
| GAS |
Geometry Acceleration Structures |
JUNO: 10 GAS created from 10 CSGSolid (which refs CSGPrim,CSGNode ) |
JUNO : Geant4 ~300k volumes "factorized" into 1 OptiX IAS referencing ~10 GAS
cxr_overview_emm_t0_elv_t_moi__ALL_with-debug-disable-xj.jpg
cxr_min__eye_-10,0,0__zoom_1__tmin_0.1__sChimneyAcrylic_altview.jpg
Raytrace render view from inside JUNO Water Buffer
cxr_min__eye_-30,0,5__zoom_1__tmin_25__sChimneyAcrylic_tmin_cutaway.jpg
ray TMIN cuts away sphere
cxr_min__eye_-30,0,5__zoom_1__tmin_25__sChimneyAcrylic_skip_target_acrylic.jpg
ELV=t94,95 ./cxr_min.sh ## skip sTarget sAcrylic
cxr_min__eye_-10,0,0__zoom_0.5__tmin_0.1__sChimneyAcrylic_increased_TMAX.jpg
Increase TMAX to avoid cutoff
cxr_min__eye_-10,0,-30__zoom_0.5__tmin_0.1__sChimneyAcrylic_photon_eye_view.jpg
ELV=t94,95 ./cxr_min.sh ## skip sTarget sAcrylic : upwards view
cxr_overview_emm_image_grid_overview
- Comparison of ray traced render times of different geometry
- simple way to find issues, eg over complex CSG, overlarge BBox
cxr_view_emm_t0_elv_t142_eye_-1,-1,-1,1__zoom_1__tmin_0.4__sWaterTube_skip_sBottomRock.jpg
Render inside JUNO water buffer : PMTs, chimney, support sticks
image_grid_elv_scan.jpg
Spot the differences : from volume exclusions
cxr_overview.sh ELV scan 1080x1920 2M (NVIDIA TITAN RTX)
| idx |
-e |
time(s) |
relative |
enabled geometry description |
|---|
| 0 |
t133 |
0.0077 |
0.9347 |
EXCL: sReflectorInCD |
| 1 |
t37 |
0.0079 |
0.9518 |
EXCL: GLw1.bt08_bt09_FlangeI_Web_FlangeII |
| 2 |
t74 |
0.0079 |
0.9616 |
EXCL: GZ1.B06_07_FlangeI_Web_FlangeII |
| ... |
| 35 |
t |
0.0083 |
1.0000 |
ALL |
| ... |
| 141 |
t50 |
0.0097 |
1.1750 |
EXCL: GLb1.up01_FlangeI_Web_FlangeII |
| 142 |
t39 |
0.0097 |
1.1751 |
EXCL: GLw1.bt10_bt11_FlangeI_Web_FlangeII |
| 143 |
t123 |
0.0097 |
1.1753 |
EXCL: PMT_3inch_inner1_solid_ell_helper |
| 144 |
t46 |
0.0097 |
1.1758 |
EXCL: GLb1.up05_FlangeI_Web_FlangeII |
| 145 |
t16 |
0.0102 |
1.2320 |
EXCL: sExpRockBox |
Dynamic geometry : excluding volumes of each of 146 solids (after excluding slowest: solidXJfixture)
- time range : 0.0077->0.0102 s (~ +-20% )
- reproducibility ~+-10%
Small time range suggests no major geometry performance issues remain, after excluding slowest
- solids with deep CSG trees (eg solidXJfixture) can cause >2x slow downs
n-ary CSG Compound "List-Nodes" => Much Smaller CSG trees
- Communicate shape more precisely
- => better suited intersect alg => less resources => faster
Generalized Opticks CSG into three levels : tree < node < leaf
Generalizes binary to n-ary CSG trees
- list-node references sub-nodes by subNum subOffset
- CSG_CONTIGUOUS Union
- user guarantees contiguous, like G4MultiUnion of prim
- CSG_DISCONTIGUOUS Union
- user guarantees no overlaps, eg "union of holes" to be CSG subtracted : => simple, low resource intersect
- CSG_OVERLAP Intersection
- user guarantees overlap, eg general G4Sphere: inner radius, thetacut, phicut
Promising approach to avoid slowdowns from complex CSG solids
QUDARap : CUDA Optical Simulation Implementation
CPU/GPU Counterpart Code Organization for Simulation
| |
CPU |
GPU |
|---|
| context steering |
QSim.hh |
qsim.h |
| curandState setup |
QRng.hh |
qrng.h |
| property interpolation |
QProp.hh |
qprop.h |
| event handling |
QEvent.hh |
qevent.h |
| Cerenkov generation |
QCerenkov.hh |
qcerenkov.h |
| Scintillation generation |
QScint.hh |
qscint.h |
| texture handling |
QTex.hh |
cudaTextureObject_t |
- facilitate fine-grained modular testing
- bulk of GPU code in simple to test headers
- test most "GPU" code on CPU, eg using mock curand
- QUDARap does not depend on OptiX -> more flexible -> simpler testing
Validation of Opticks Simulation(A) by Comparison with Geant4 Sim. (B)
A and B always same photon counts (due to gensteps)
- direct comparison when simulations are random aligned
- when not aligned : statistical Chi2 history comparison
- compare history frequencies, Chi2 points to issues
Primary Issue : double vs float, also:
- geometry bugs : overlaps, coincident faces
- grazing incidence, edge skimmers
After debugged : fraction of percent diffs
Optical Performance : Very dependent on geometry + modelling
After avoiding geometry problems : G4Torus, deep CSG trees
- have achieved > 1500x Geant4 [1]
- removes optical bottlenecks : memory + processing
[1] Single threaded Geant4 10.4.2, NVIDIA Quadro RTX 8000 (48G), 1st gen RTX, ancient JUNO geom, OptiX 6.5, ancient Opticks
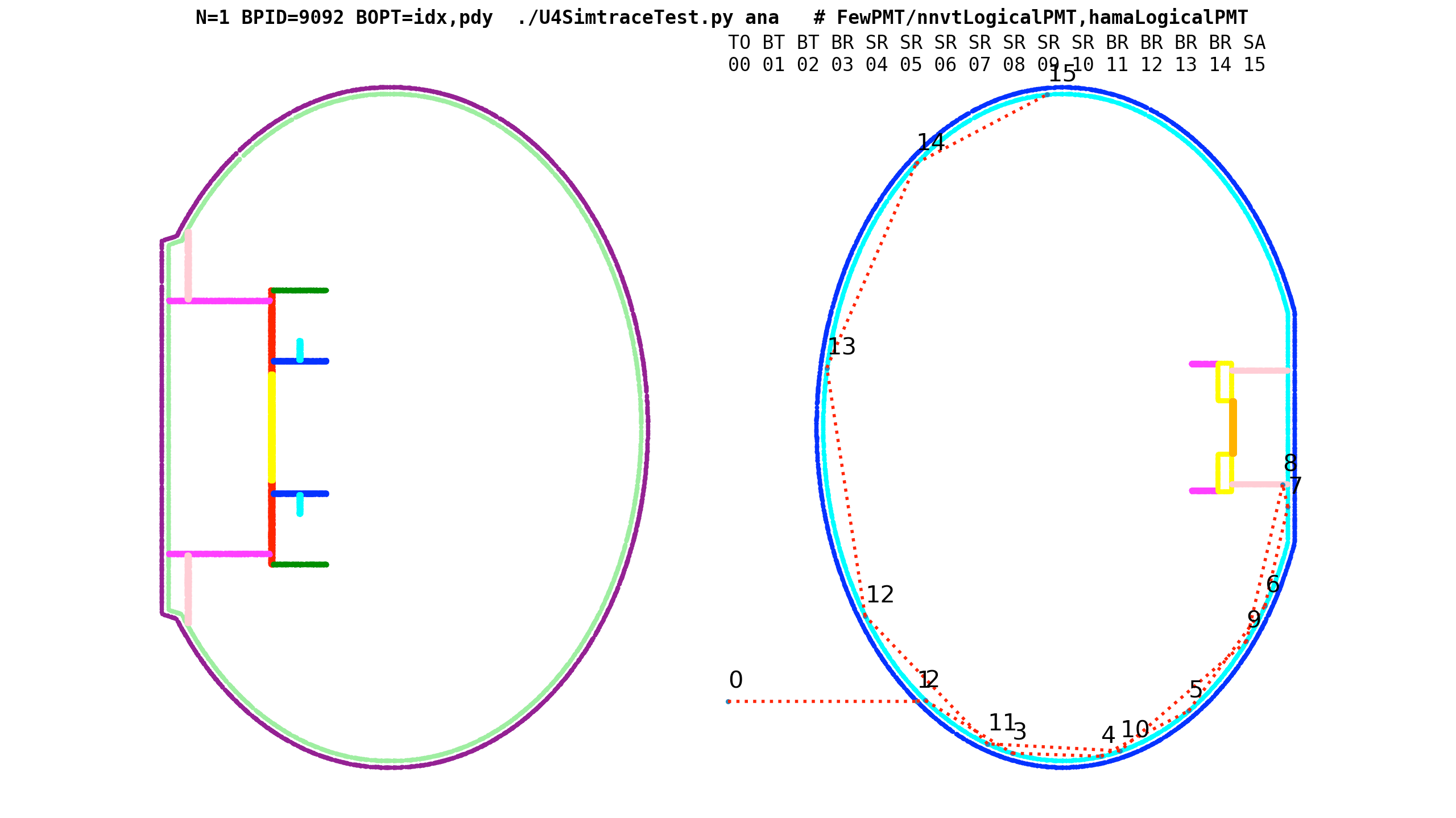
B_V1J008_N1_ip_MOI_Hama:0:1000_yy_frame_close.png
Green : start position (100k input photons)
Red : end position, Cyan : other position
B_V1J008_N1_ip_MOI_Hama:0:1000_b.png
cd ~/j/ntds ; N=1 ./ntds.sh ana
Geant4/U4Recorder 3D photon points transformed into target frame, viewed in 2D
B_V1J008_N1_OIPF_NNVT:0:1000_gridxy.png
export OPTICKS_INPUT_PHOTON=GridXY_X1000_Z1000_40k_f8.npy
export OPTICKS_INPUT_PHOTON_FRAME=NNVT:0:1000
MODE=3 EDL=1 N=0 EYE=500,0,2300 CHECK=not_first ~/j/ntds/ntds.sh ana
Photon step points from grid of input photons target NNVT:0:1000 (POM:1)
cxr_min__eye_1,0,5__zoom_2__tmin_0.5__NNVT:0:1000_demo.jpg
ray traced renders : exact same geometry "seen" by simulation
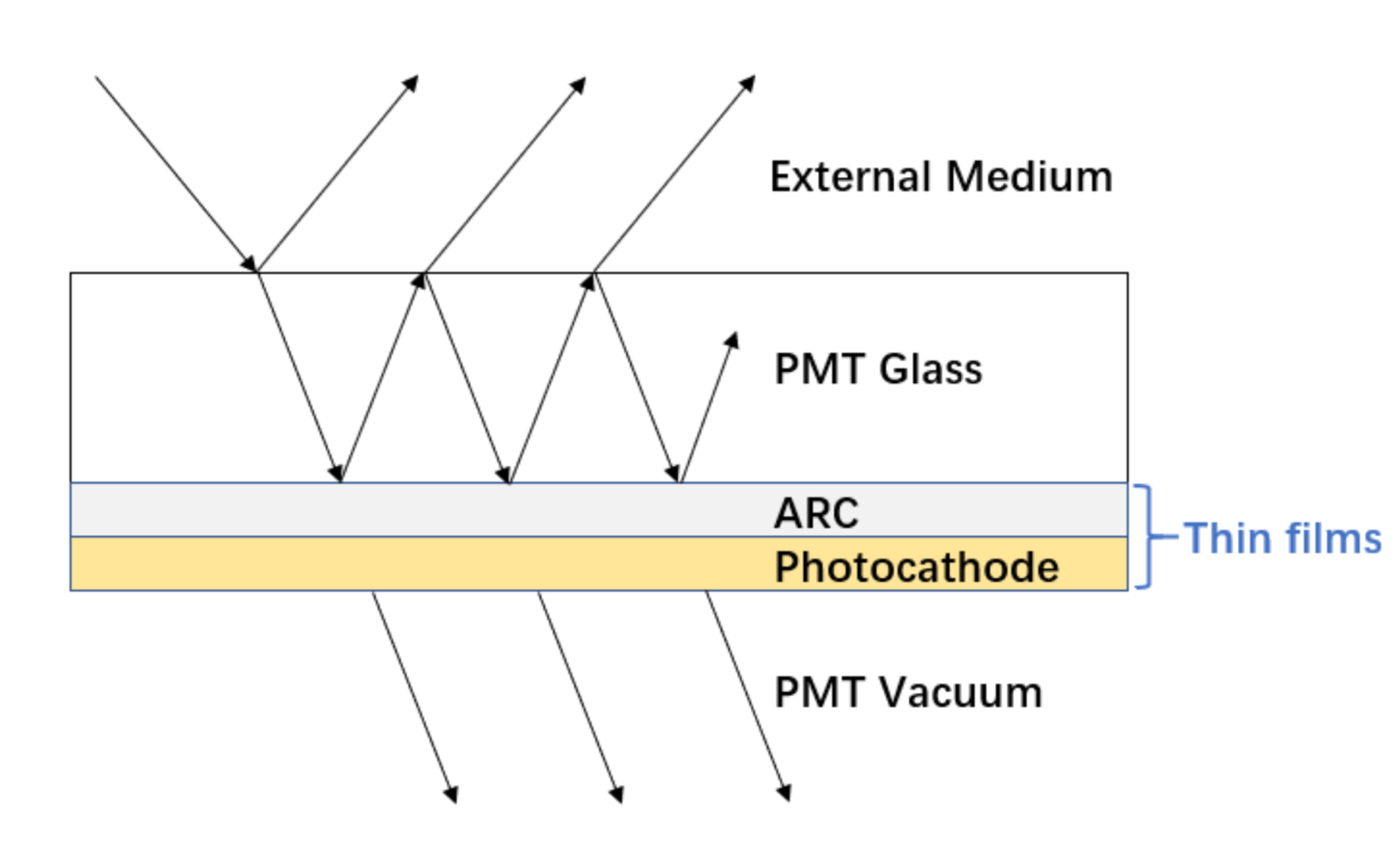
Multi-Layer Thin Film (A,R,T) Calc using TMM Calc (Custom4 Package)
- C4OpBoundaryProcess.hh
- G4OpBoundaryProcess with C4CustomART.h
- C4CustomART.h
- integrate custom boundary process and TMM calculation
- C4MultiLayrStack.h : CPU/GPU TMM calculation of (A,R,T)
based on complex refractive indices and layer thicknesses
- GPU: using thrust::complex CPU:using std::complex
Custom4: Simplifies JUNO PMT Optical Model + Geometry
Summary and Links
Opticks : state-of-the-art GPU ray traced optical simulation integrated with Geant4.
Full re-implementation of Opticks geometry and simulation for NVIDIA OptiX 7 completed.
- NVIDIA Ray Trace Performance continues rapid progress (2x each generation)
- any simulation limited by optical photons can benefit from Opticks
- more photon limited -> more overall speedup (99% -> 100x)